白辰甲
Research Scientist
Institute of Artificial Intelligence (TeleAI), China Telecom
Biography
I am a Research Scientist at Institute of Artificial Intelligence (TeleAI), China Telecom and the Director of Embodied AI research center, specialized in the cutting-edge field of Embodied AI and Reinforcement Learning (RL). Our group is dedicated to develop embodied technologies encompassing perception, planning, locomotion, manipulation, and promoting the industrial application of embodied AI. Our group thrives under the leadership of Prof. Xuelong Li, who serves as the dean of TeleAI. Previously, I was a Researcher at Shanghai AI Laboratory, affiliated with IPEC group. My research interests include diffusion/transformer policy, LLM-driven planning, world model, preference learning, RL/MPC-based locomotion, dexterous manipulation, representation learning, sim-to-real, multi-agent collaboration, as well as real-world applications for robot arm, dexterous hand, quadruped robot, and humanoid robot.
I holds a Ph.D. degree in Computer Science from Harbin Institute of Technology (HIT), advised by Prof. Peng Liu. I am fortunate to have been collaborated with many fantastic researchers. I was a joint PhD student at University of Toronto and Vector Institute, working with Prof. Animesh Garg. I also used to be an intern at Huawei Noah’s Ark Lab (advised by Prof. Jianye Hao), Tencent Robotics X (advised by Dr. Lei Han), and Alibaba. I received my Bachelor’s degree and Master’s degree in Computer Science from HIT.
中文简介:白辰甲,博士,现任中国电信人工智能研究院(TeleAI)研究科学家,具身智能团队负责人。研究方向包括具身智能、人形机器人、运动和操作大模型、推理对齐等。在包括AI Journal、TPAMI、NeurIPS等学术会议和期刊上发表论文50余篇,出版专著一部。主持国家自然科学基金、国家重点研发计划课题。入选中国科协青年托举人才、上海市启明星扬帆计划、上海市光启青年人才,获世界人工智能大会优秀论文提名奖,哈工大优秀博士论文奖,并担任多个国际顶级会议和期刊的领域主席和审稿人。
团队招收具身智能方向全职研究人员、实习生、联培博士生,具体详见链接.
- Embodied AI
- Reinforcement Learning
- Foundation Model for Decision Making
PhD in Computer Science, 2017-2022
Harbin Institute of Technology
Joint PhD Program, 2020-2022
University of Toronto

Publications
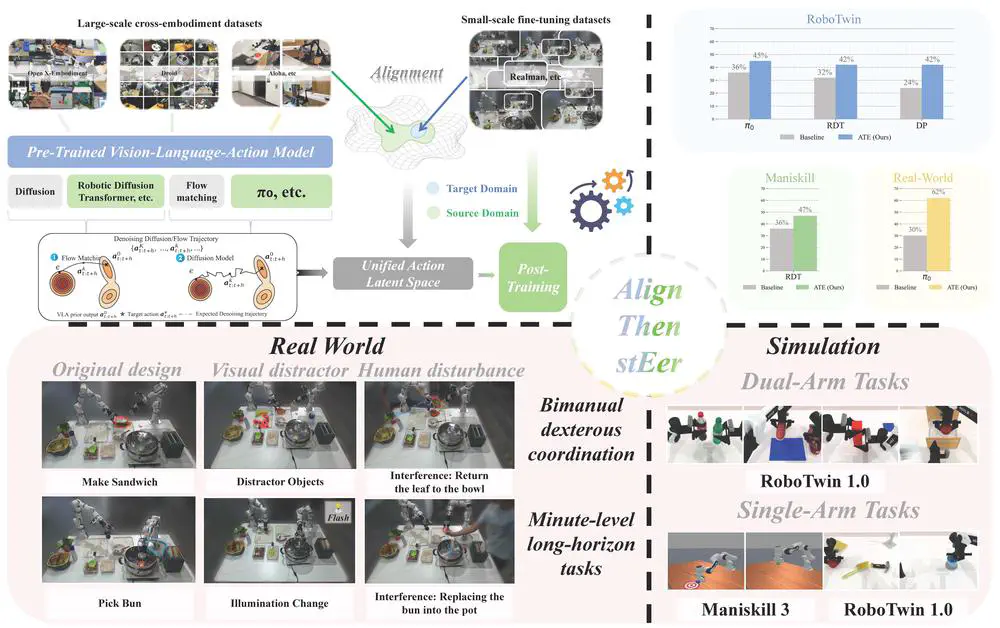

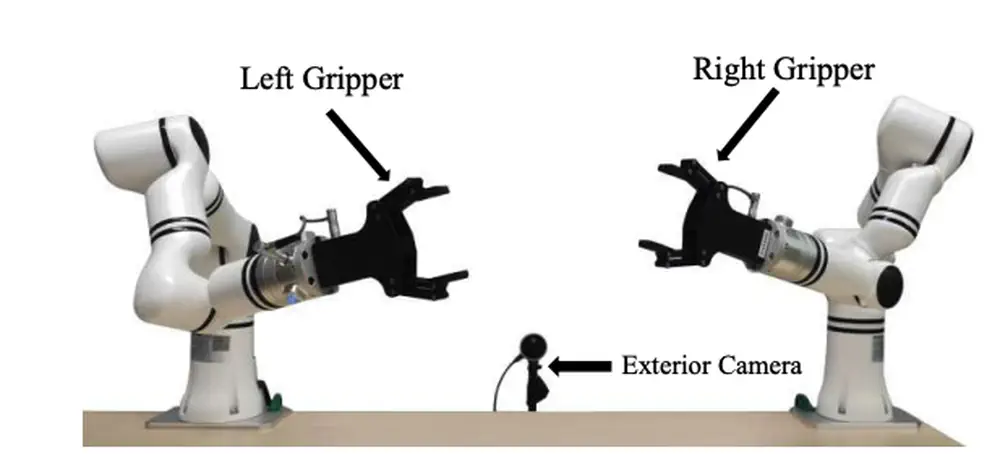
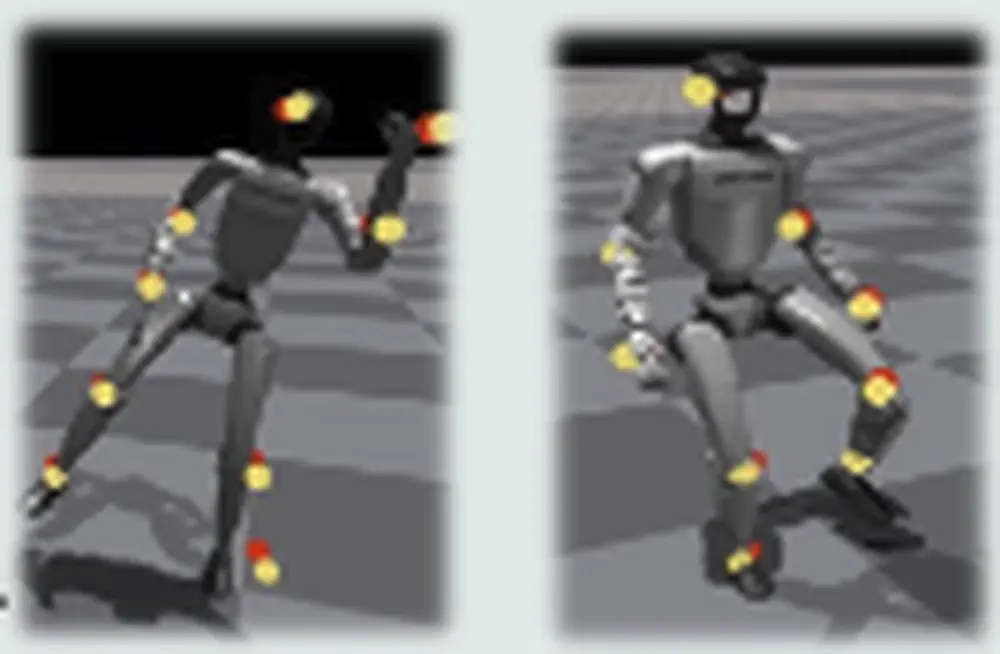



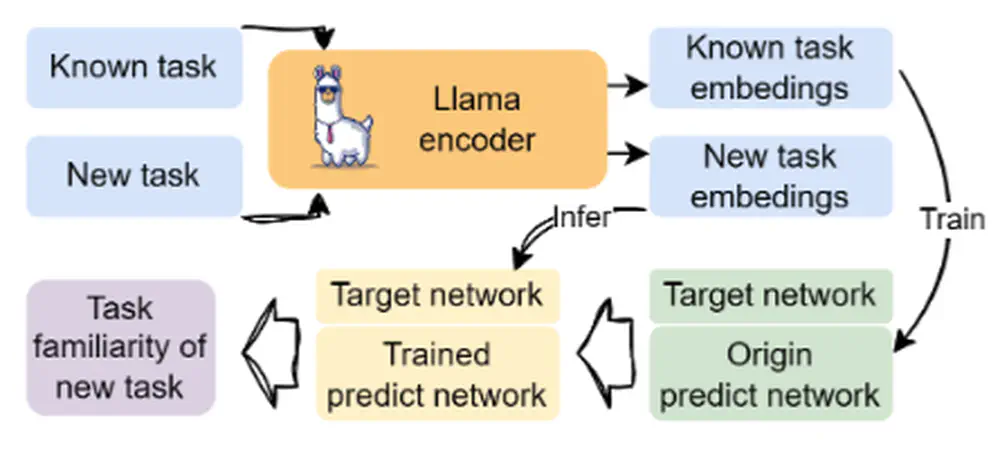
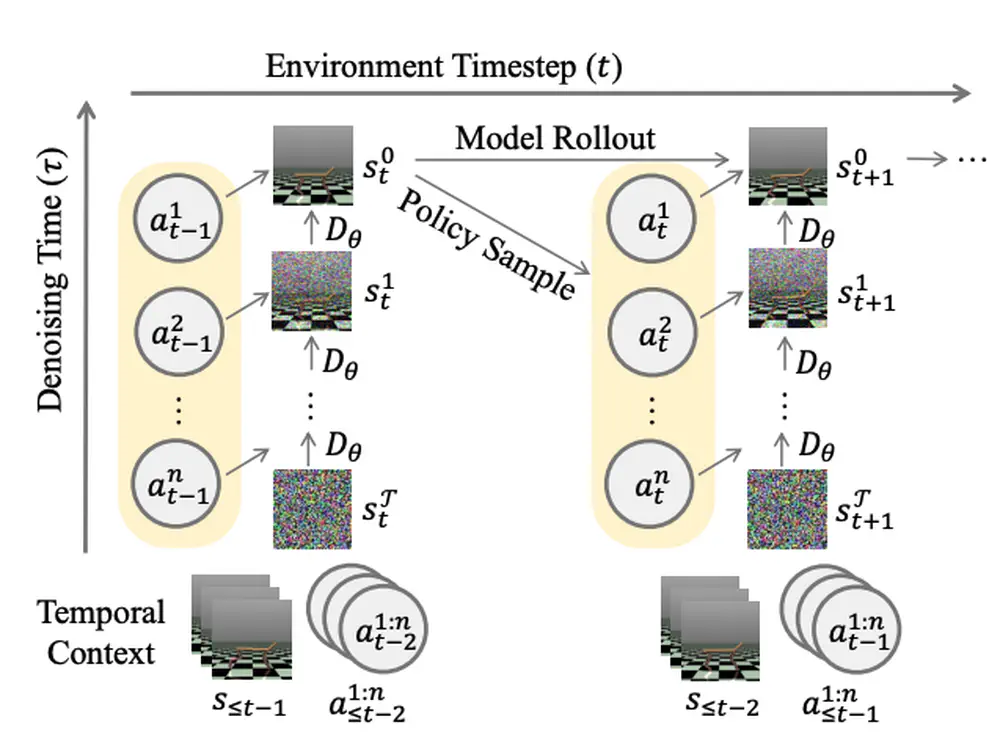
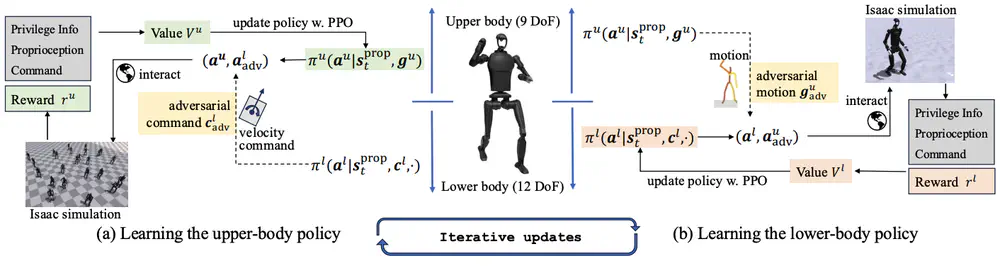
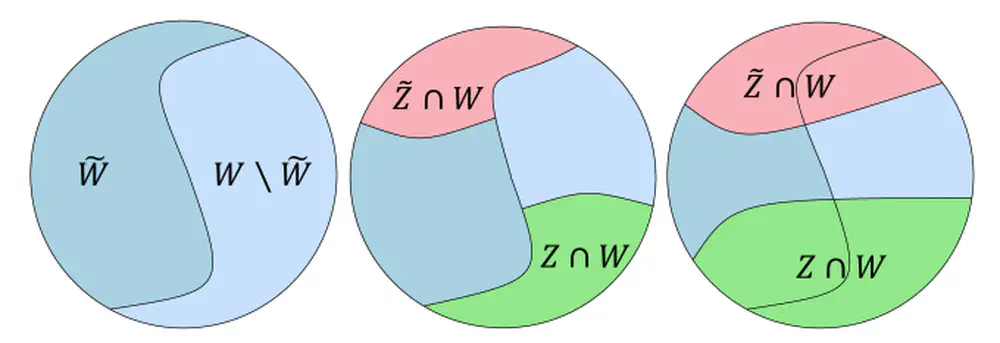

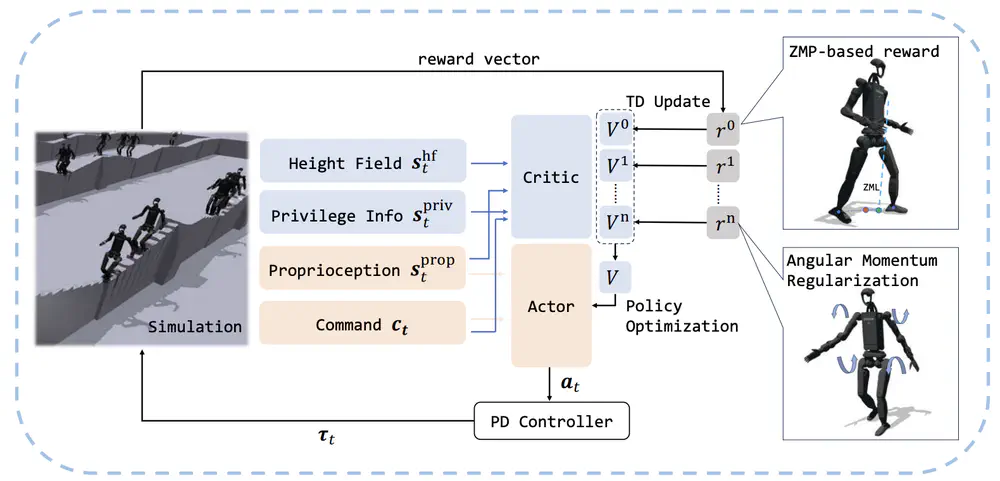
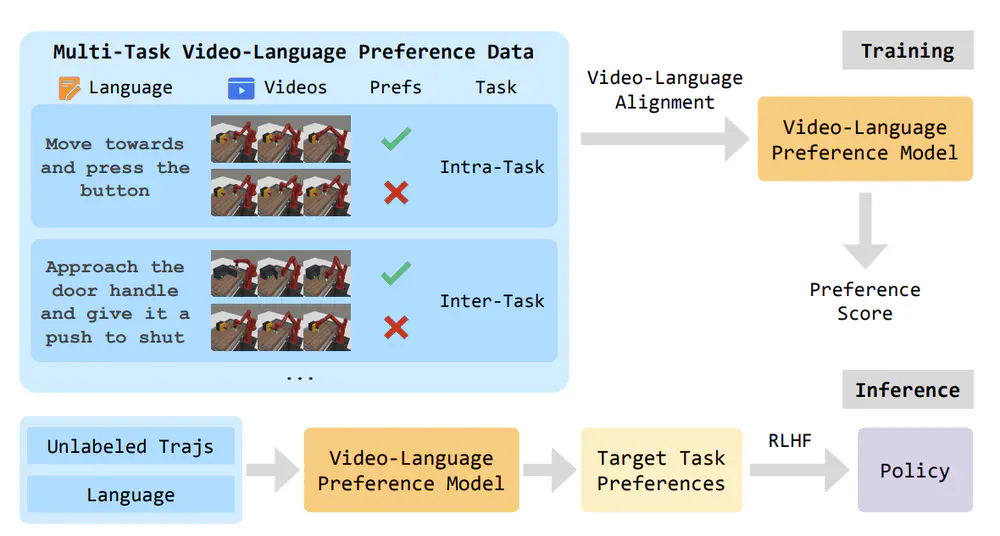
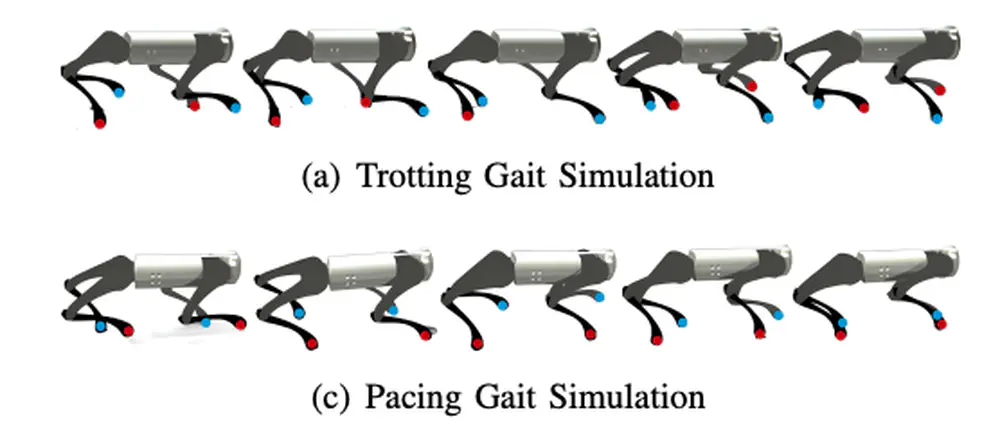

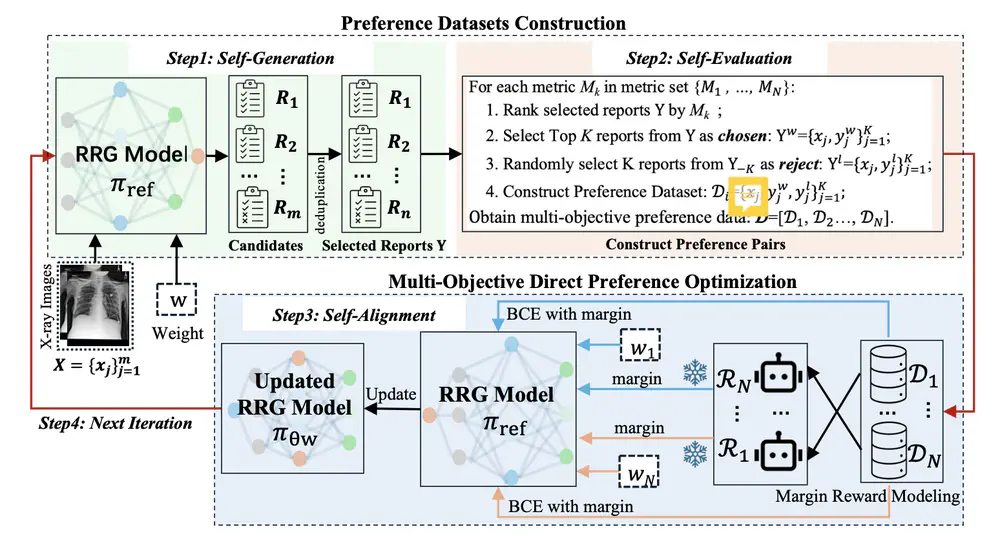
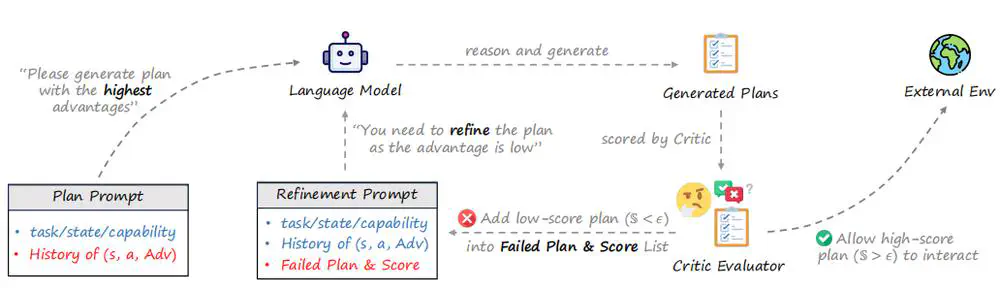
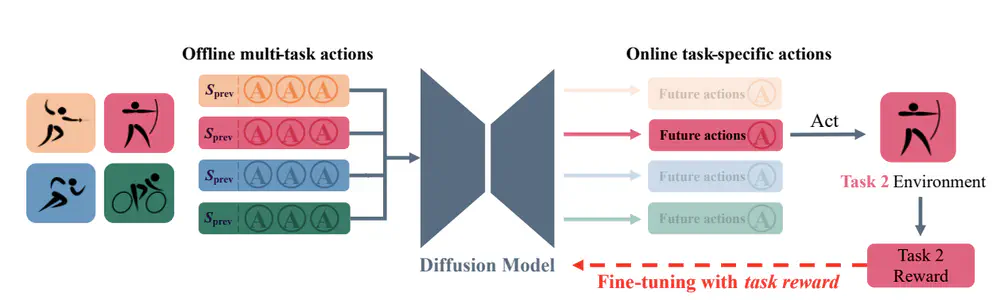
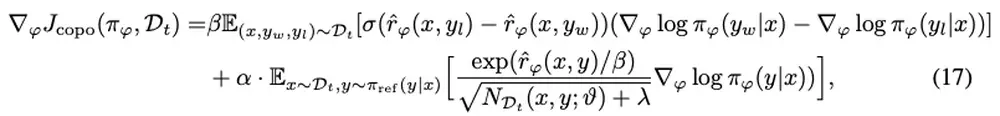
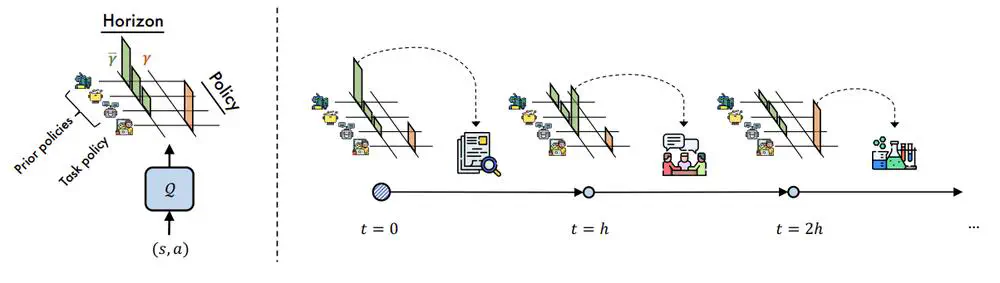
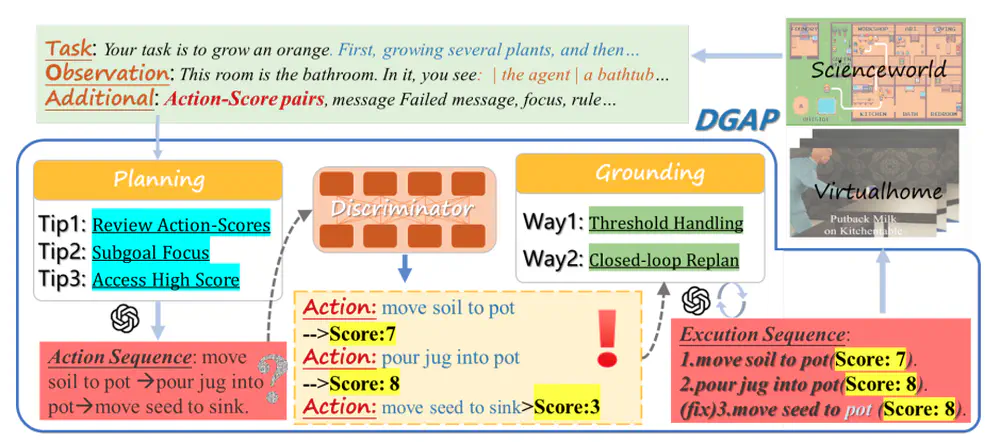
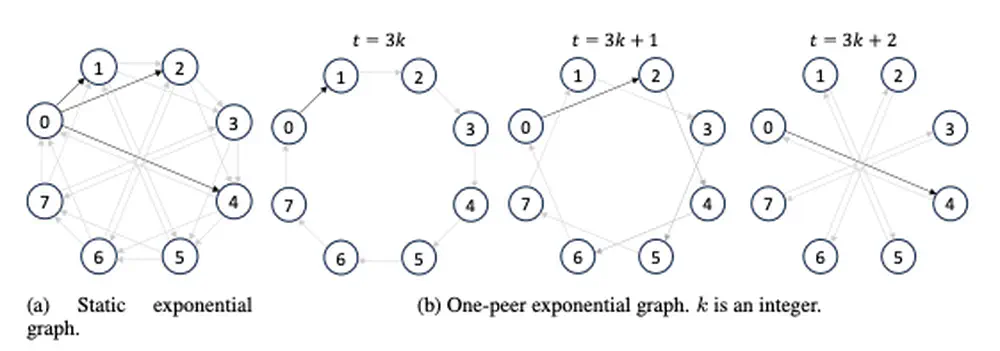
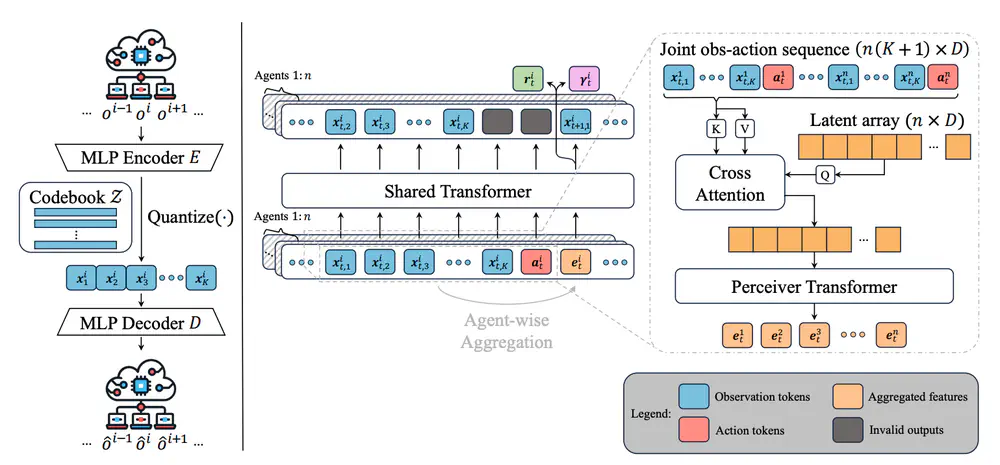
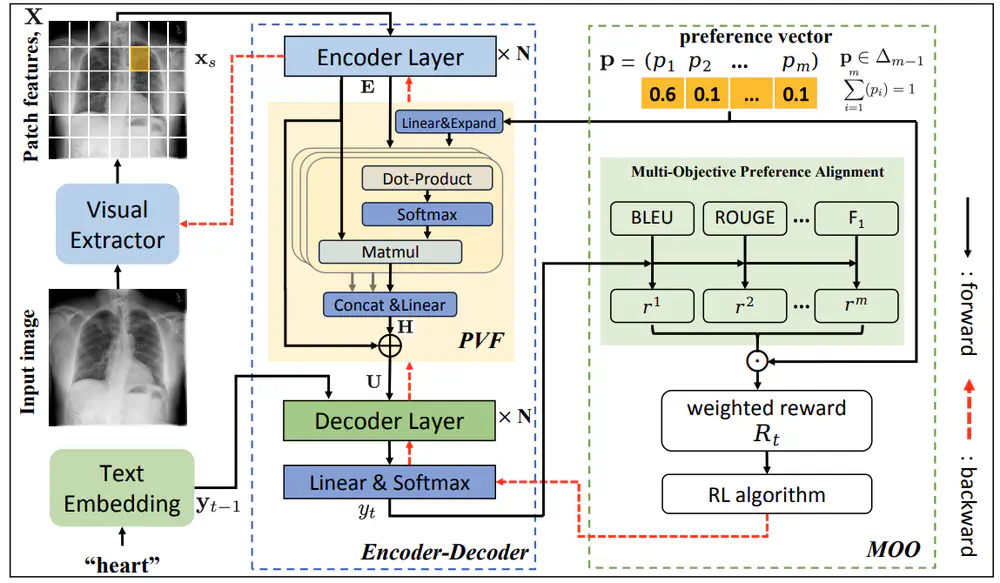
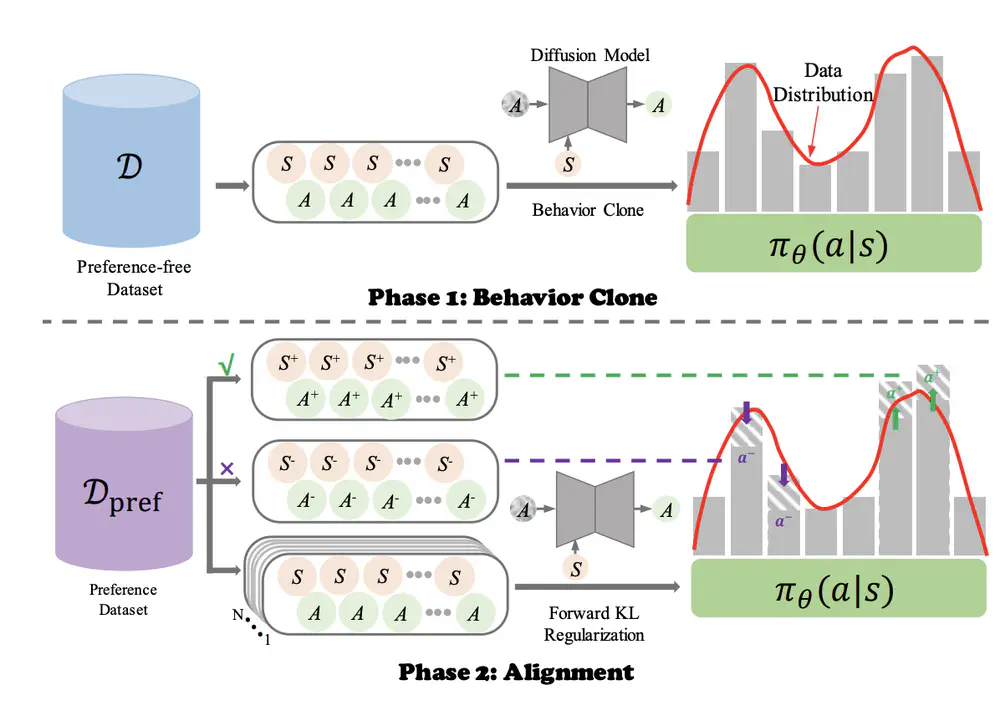
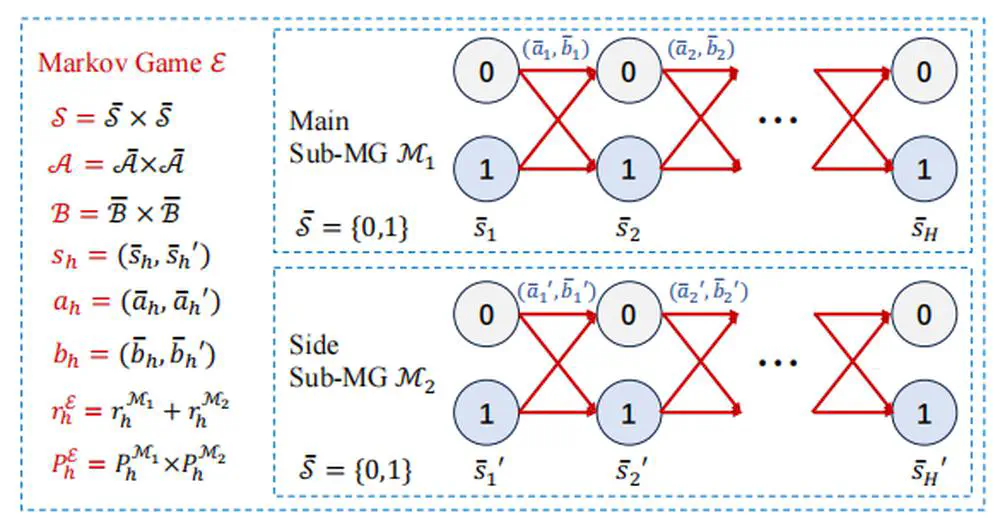
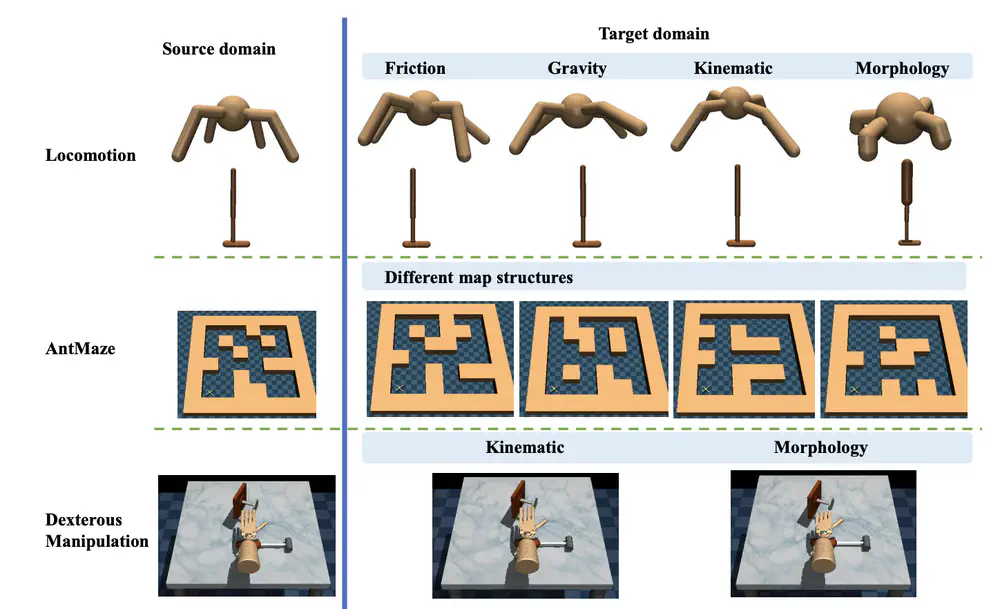
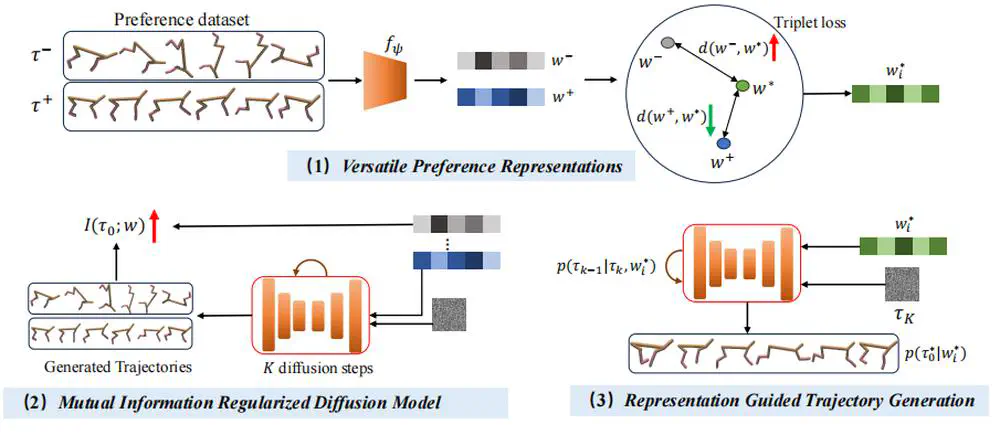
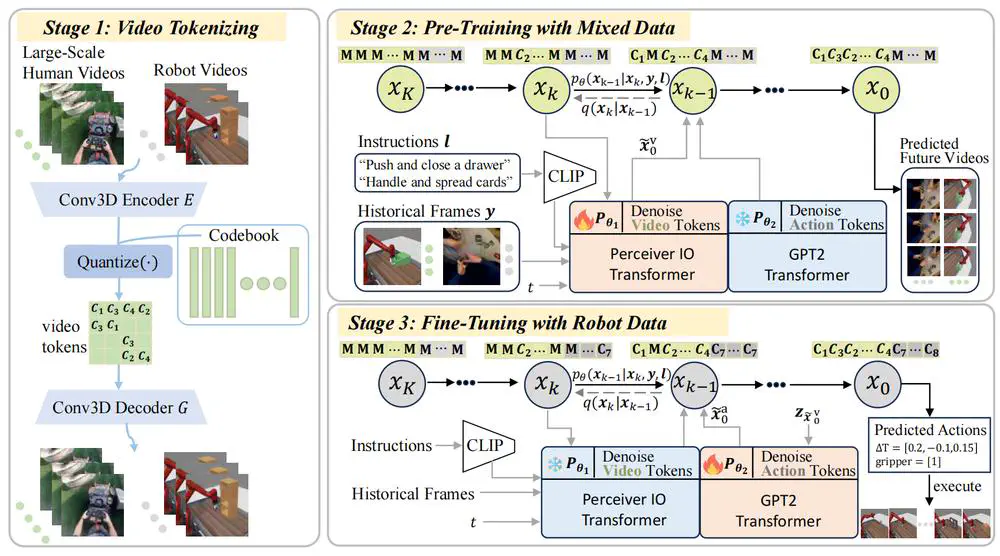
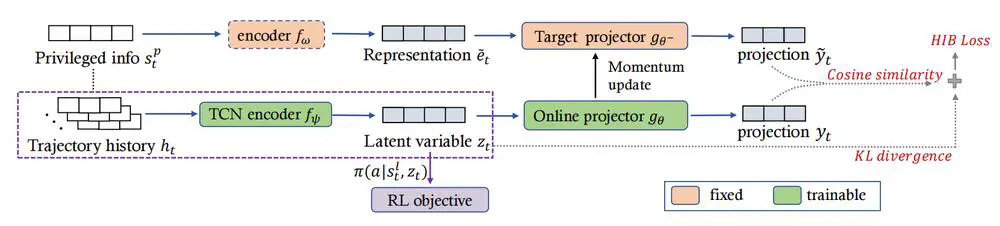
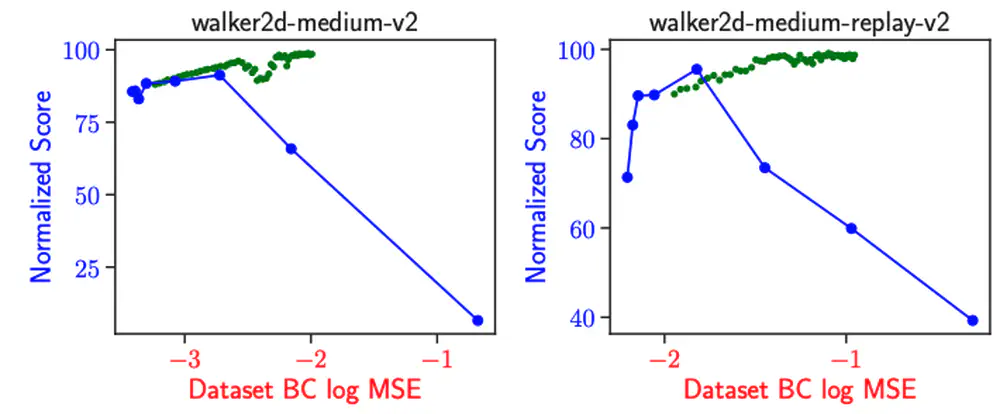
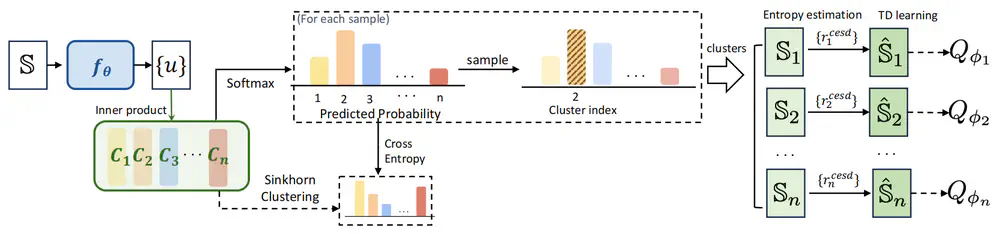

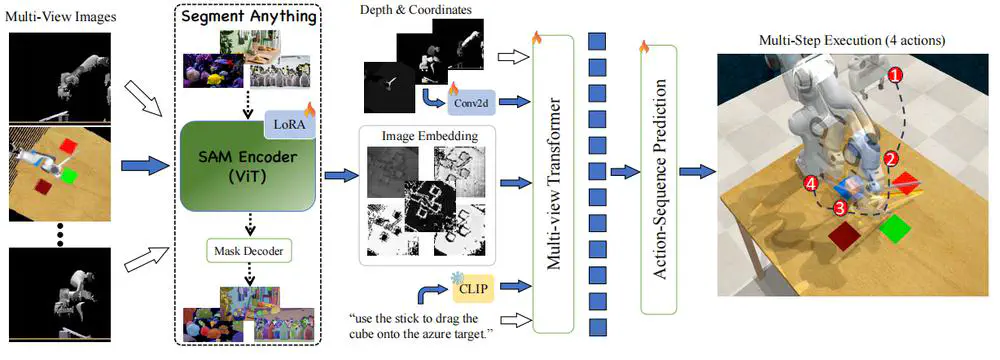
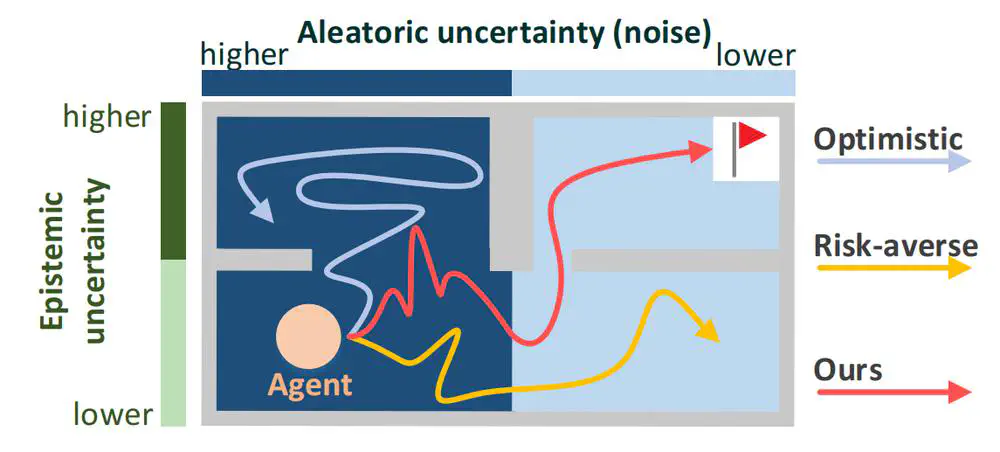
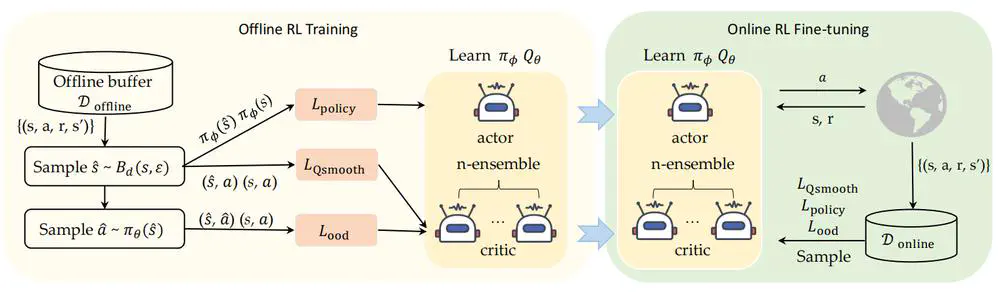
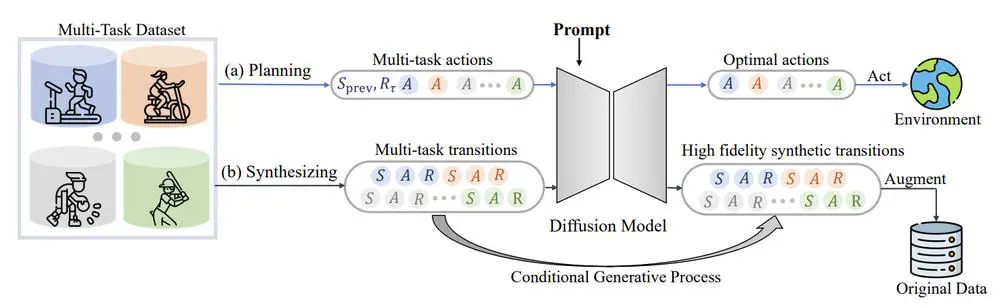
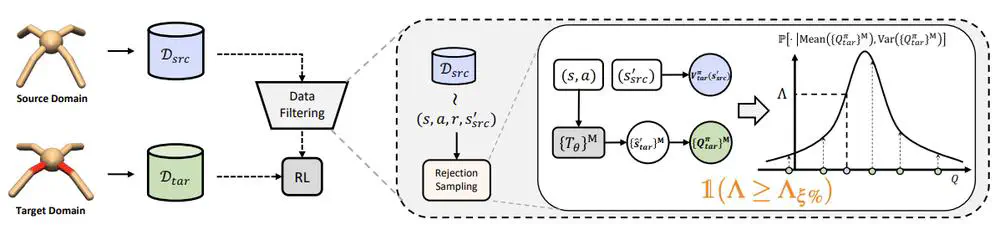
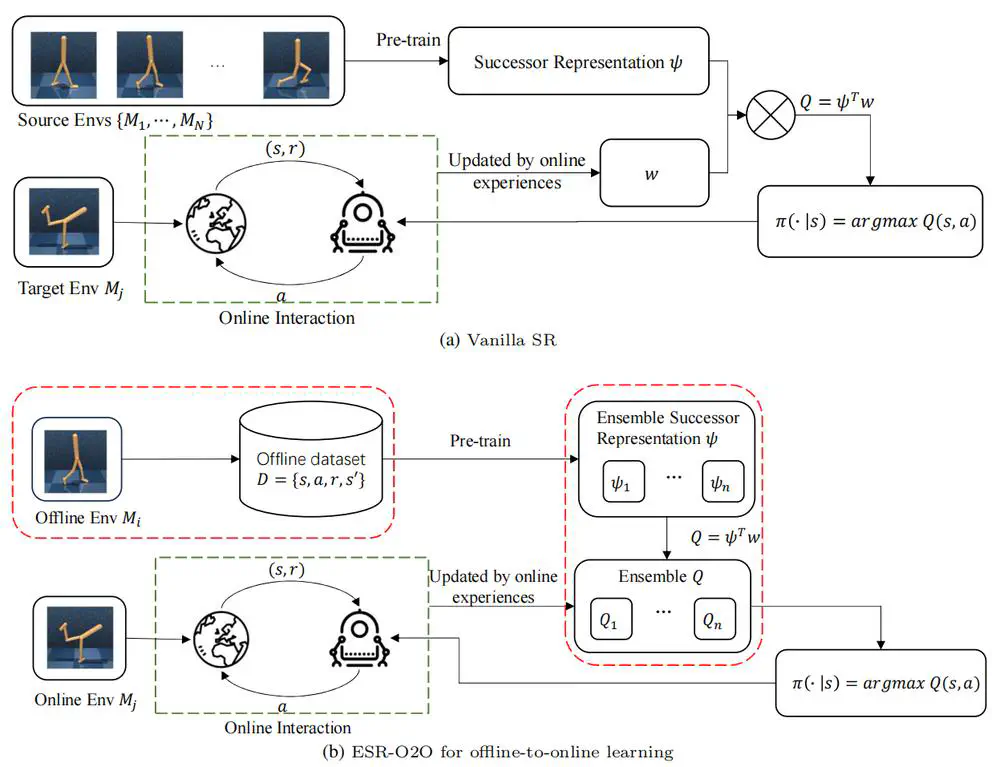
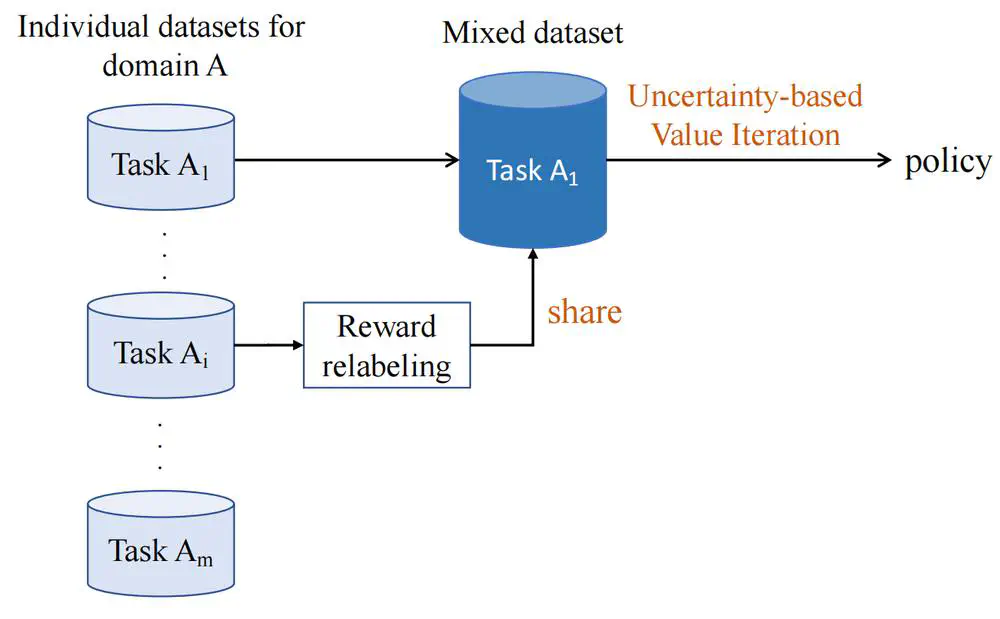
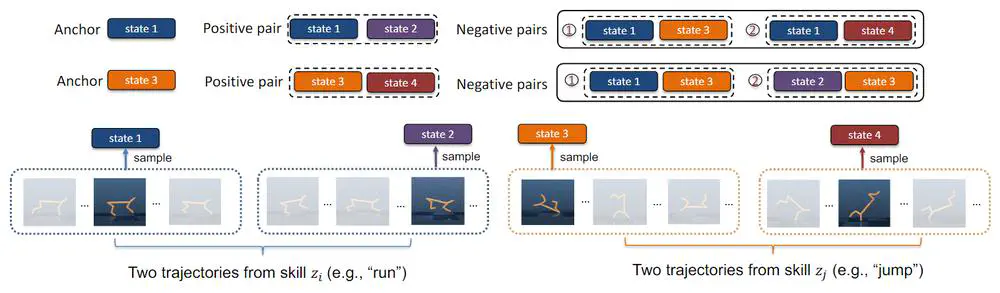
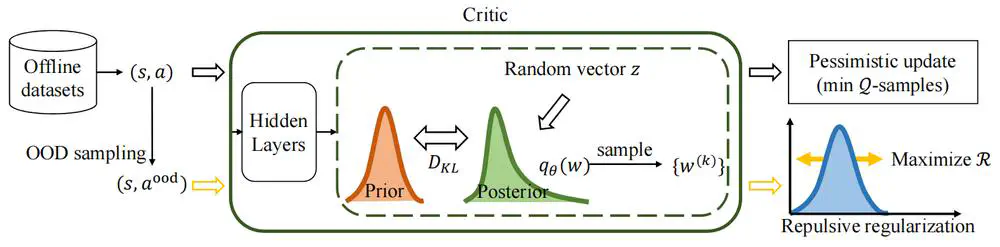
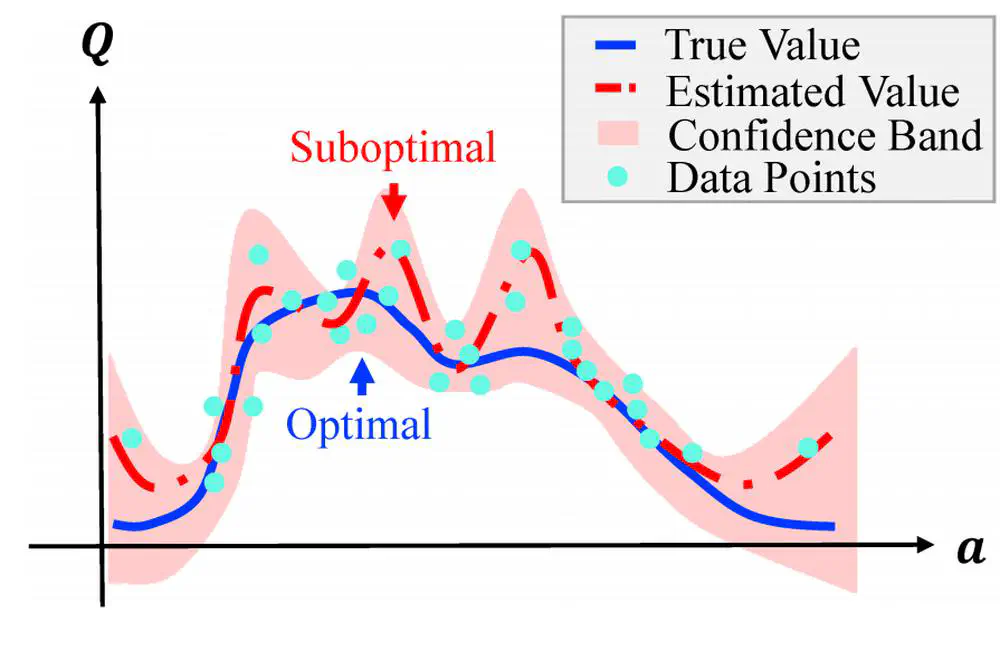
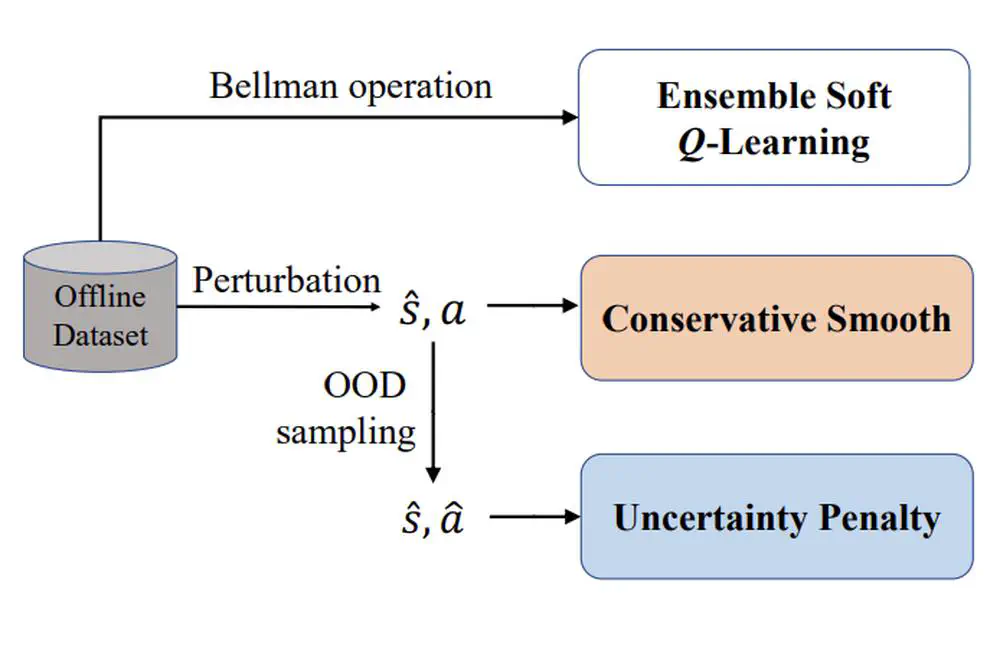
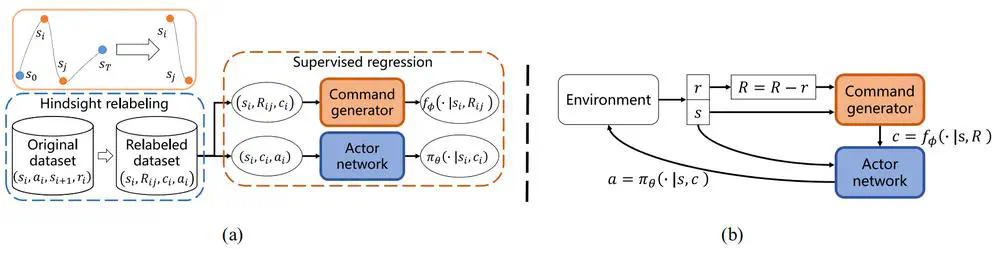
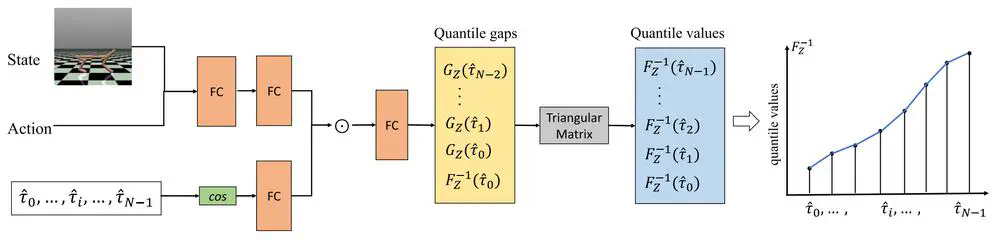
Talks
- 中国空间智能大会: 空间智能与人形机器人论坛. 中国图象图形学学会 2025.
- 上海市计算机学会计算机视觉专委会学术年会: 视觉中的大模型学习论坛. 计算机学会 2025.
- 具身智能开发者大会: 人形机器人运动与交互专题论坛. 张江科学会堂 2025.
- VALSE Webinar 379: 具身智能中的多模态感知与精细操控. VALSE 2025.
- 中国具身智能大会: 模式识别与机器人论坛. 人工智能学会 2025.
- CSIG图像图形学科前沿讲习班: 小模型的曙光和机会之思辨. 图形图像学会 2025.
- 自主机器人技术研讨会(ARTS 2024): 大模型驱动的具身智能. 自动化学会 2024.
- CCF决策智能会议(RLChina): 具身智能体与机器人论坛. 计算机学会 2024.
- 中国数据挖掘会议: AI Agent与多智能体系统研讨会. 计算机学会 2024.
- 世界人工智能大会-WAIC: 青年优秀论文论坛. 上海科协 2024.
- 中国具身智能大会: 大模型与具身智能. 人工智能学会 2024.
- 上海自主智能无人系统科学中心: 智能决策学术报告. 同济大学 2023.
- 决策智能峰会: 决策大模型论坛. DataFun 2023.
- 多智能体强化学习讲习班: 离线强化学习和大模型. 自动化学会 2023.
- GAITC 全球人工智能技术大会: 人工智能原理专题论坛. 中国科协 2023.
- 高级人工智能公开课: 强化学习. 天津大学 2023.
- 从统计学到人工智能研讨会: 强化学习的不确定性估计. 上海财经大学 2022.
Service
- Senior Program Committee Member (SPC) / Area Chair (AC) of AAMAS (2024 - 2025)
- Area Chair (AC) of Pattern Recognition and Computer Vision (PRCV) (2025 - )
- Program Committee Members (PC) / Conference Reviewer of RSS (2024 - 2025)
- Program Committee Members (PC) / Conference Reviewer of NeurIPS (2021 - 2025)
- Program Committee Members (PC) / Conference Reviewer of ICLR (2021 - 2025)
- Program Committee Members (PC) / Conference Reviewer of ICML (2022 - 2025)
- Program Committee Members (PC) / Conference Reviewer of AAAI (2021 - 2025)
- Program Committee Members (PC) / Conference Reviewer of ICRA (2024 - 2025)
- Program Committee Members (PC) / Conference Reviewer of ECAI (2023 - 2025)
- Journal Reviewer: IEEE Trans. Cybernetics, IEEE Trans. TNNLS, IEEE Trans. TETCI, IEEE Trans. Intelligent Vehicles, Pattern Recognition.