Publications
In International Conference on Learning Representations (ICLR), 2025 Spotlight
We propose count-based online preference optimization for LLM alignment that leverages coin-flip counting to encourage exploration in online RLHF.
In International Conference on Learning Representations (ICLR), 2025
We propose a novel framework that generalizes demonstrations to establish critic-regularized grounding and optimization in the long-term planning of LLMs.
In International Conference on Learning Representations (ICLR), 2025
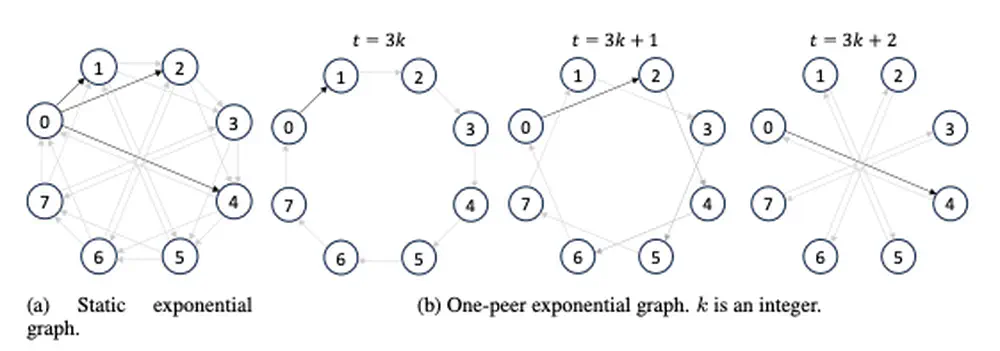
We introduce ExpoComm, a scalable communication protocol that leverages exponential topologies for efficient information dissemination among many agents in large-scale multi-agent reinforcement learning.
In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025
We develop a learning framework combining offline diffusion planner and online preference alignment with weak preference labeling for legged locomotion control.
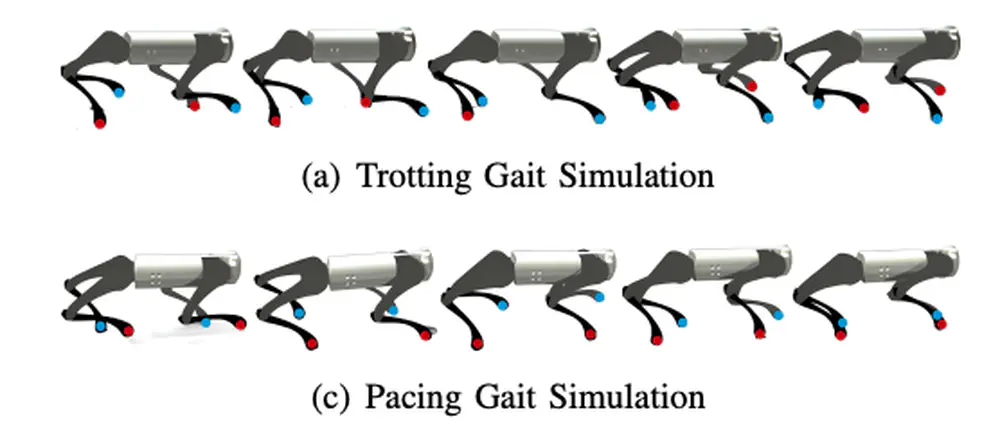
In AAAI Conference on Artificial Intelligence (AAAI), 2025
We propose a new radiology report generation method that aligns the pre-trained model with multiple human preferences via preference-guided multi-objective optimization reinforcement learning.
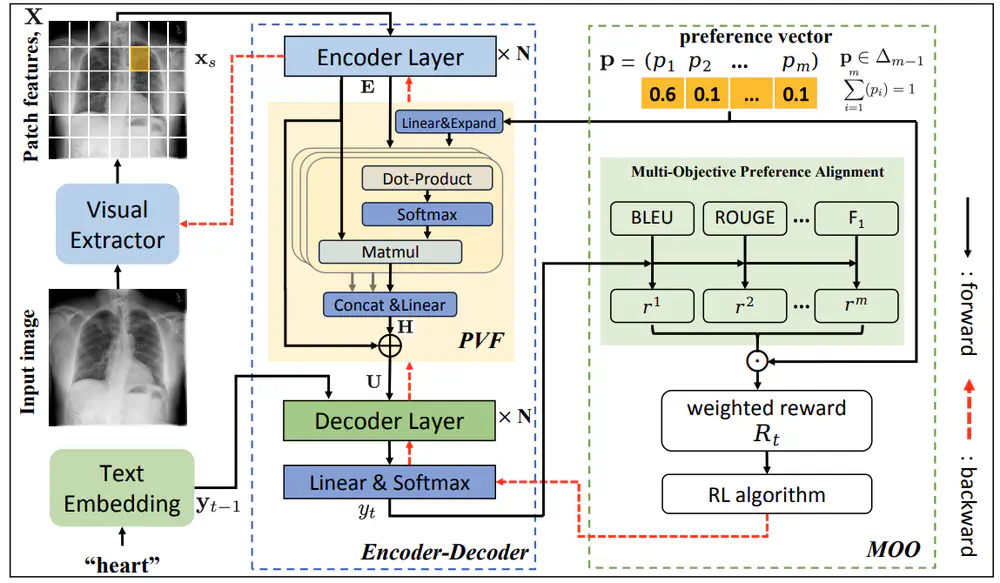
In AAAI Conference on Artificial Intelligence (AAAI), 2025
We propose Forward KL regularized Preference optimization for aligning Diffusion policies to align the diffusion policy with preferences, learning to align the policy output with human intents in various tasks.
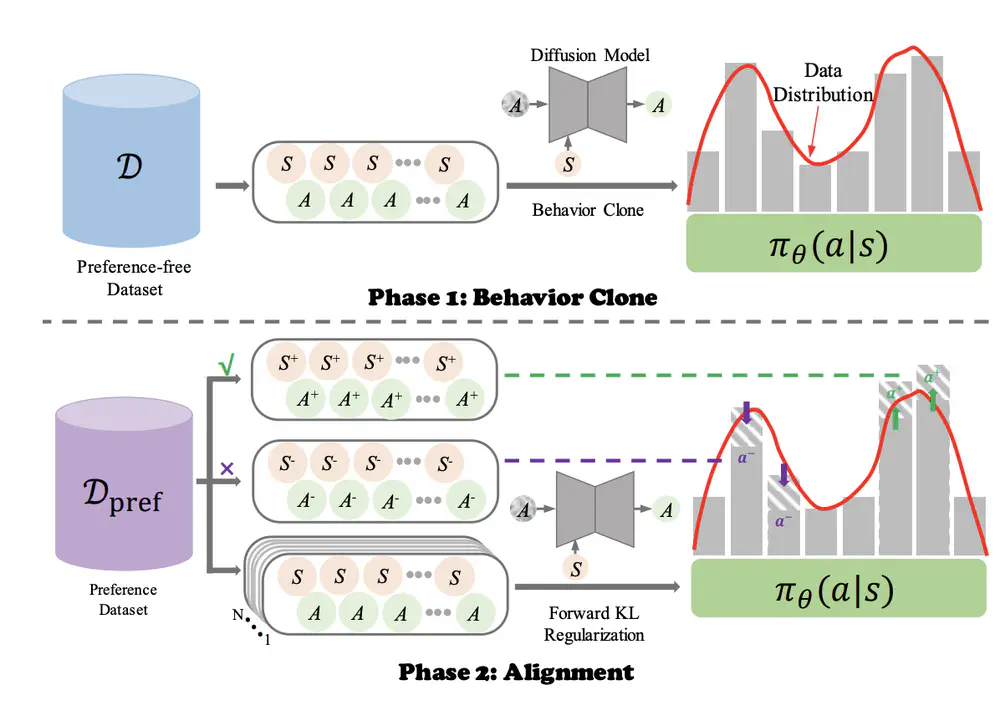
In European Conference on Artificial Intelligence (ECAI), 2024
We propose a novel dynamic policy constraint that restricts the learned policy on the samples generated by the exponentional moving average of previously learned policies for offline RL.
In Annual Meeting of the Association for Computational Linguistics (ACL), 2025
We propose an online iterative self-alignment method for radiology report generation that iteratively generates unlimited preference data and automatically aligns with radiologists’ multiple objectives.
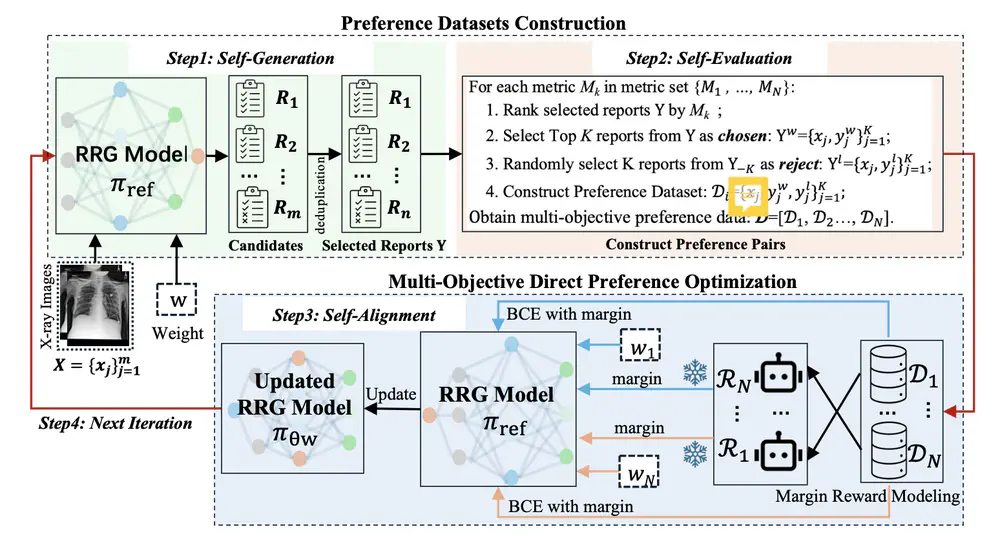
In Annual Meeting of the Association for Computational Linguistics (ACL), 2025
We propose a novel framework for multi-agent collaboration that introduces Reinforced Advantage feedback (ReAd) for efficient self-refinement of plans.
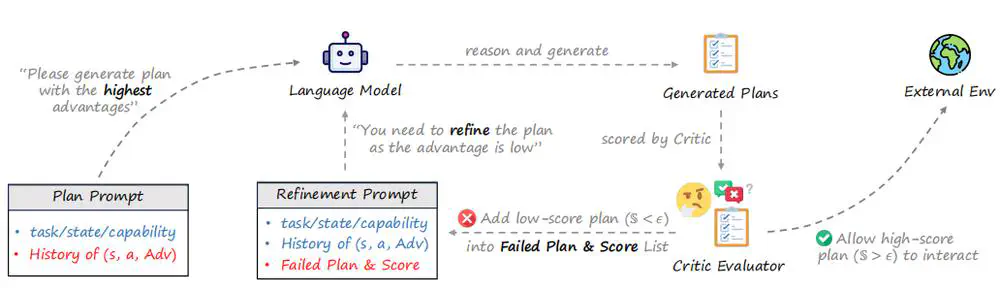
In Neural Information Processing Systems (NeurIPS), 2025
We propose CURE, a method that splits LLM planning uncertainty into epistemic and intrinsic parts for more reliable robot decision-making.
In International Conference on Machine Learning (ICML), 2024
We propose a novel representation-based approach to measure the domain gap, where the representation is learned through a contrastive objective by sampling transitions from different domains.

In International Conference on Machine Learning (ICML), 2024
We propose SAM-E, a novel architecture for robot manipulation by leveraging a vision-foundation model for generalizable scene understanding and sequence imitation for long-term action reasoning.
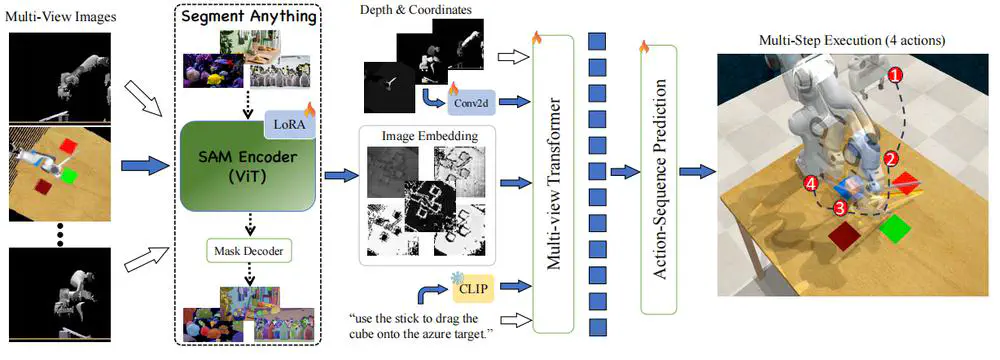
In International Conference on Machine Learning (ICML), 2024
We propose a novel unsupervised RL framework via an ensemble of skills, where each skill performs partition exploration based on the state prototypes.
In Neural Information Processing Systems (NeurIPS), 2024
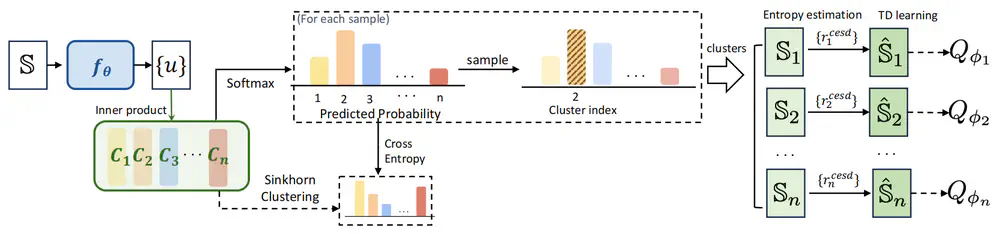
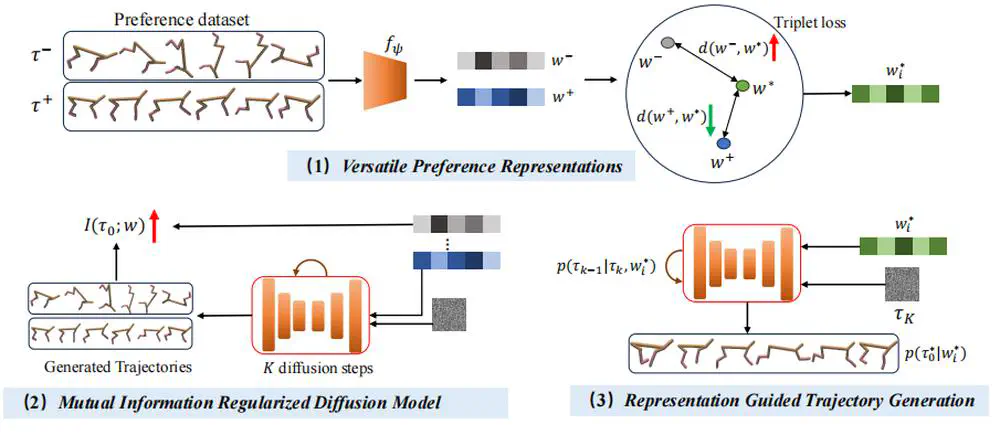
We adopt multi-task preferences as a unified condition for both single- and multi-task decision-making, and propose preference representations aligned with preference labels.
In International Conference on Machine Learning (ICML), 2024
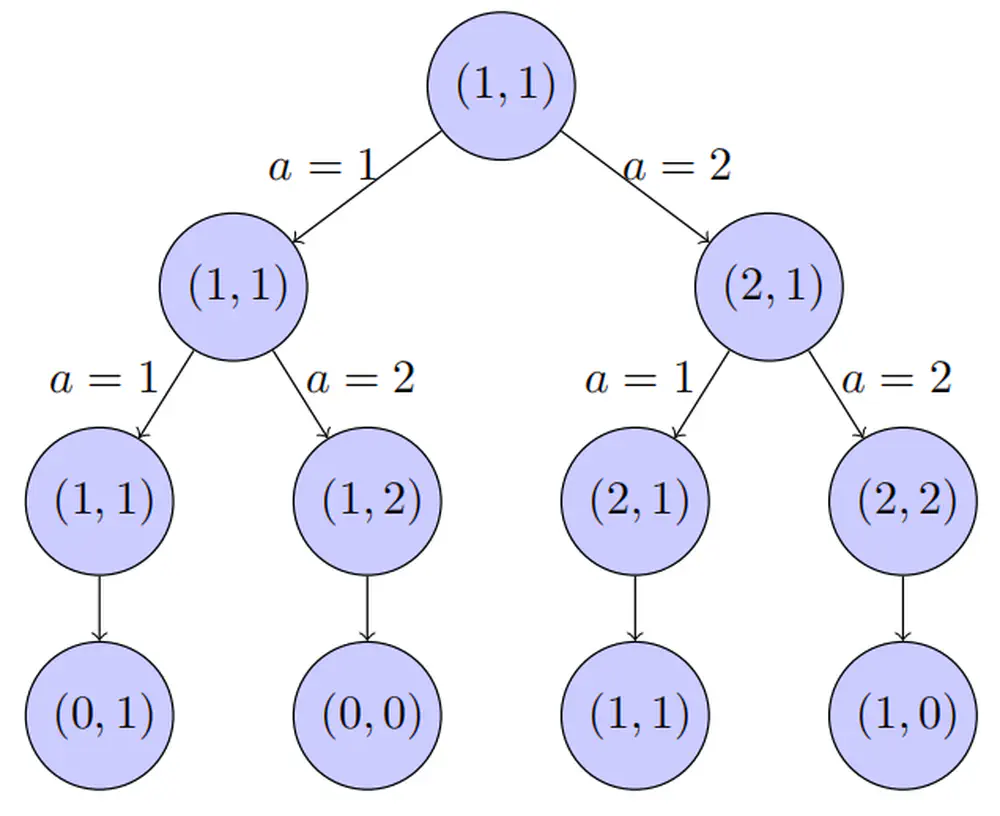
We construct an example to show the information-theoretical improvement in sample efficiency achieved by goal relabeling and develop an RL algorithm called GOALIVE.
In International Conference on Machine Learning (ICML), 2024
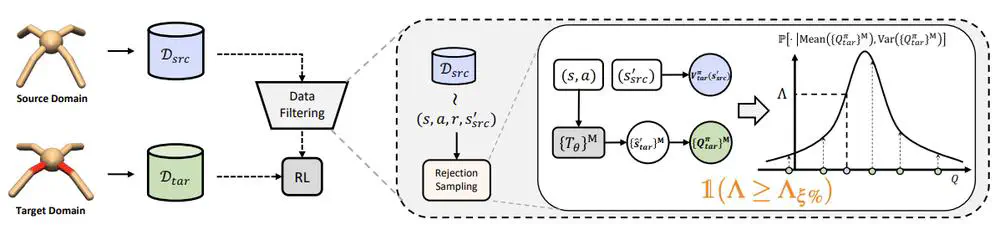
We consider dynamics adaptation settings where there exists dynamics mismatch between the source domain and the target domain, and one can get access to sufficient source domain data, while can only have limited interactions with the target domain.
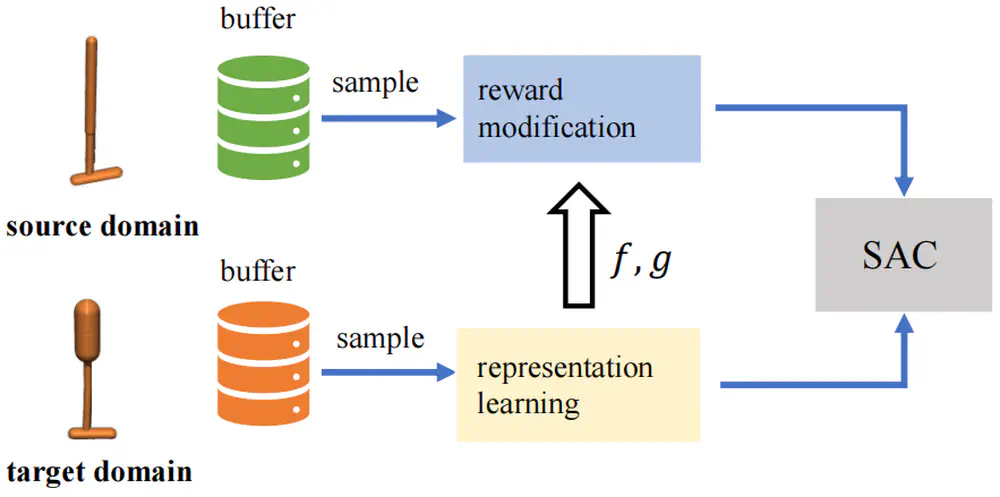
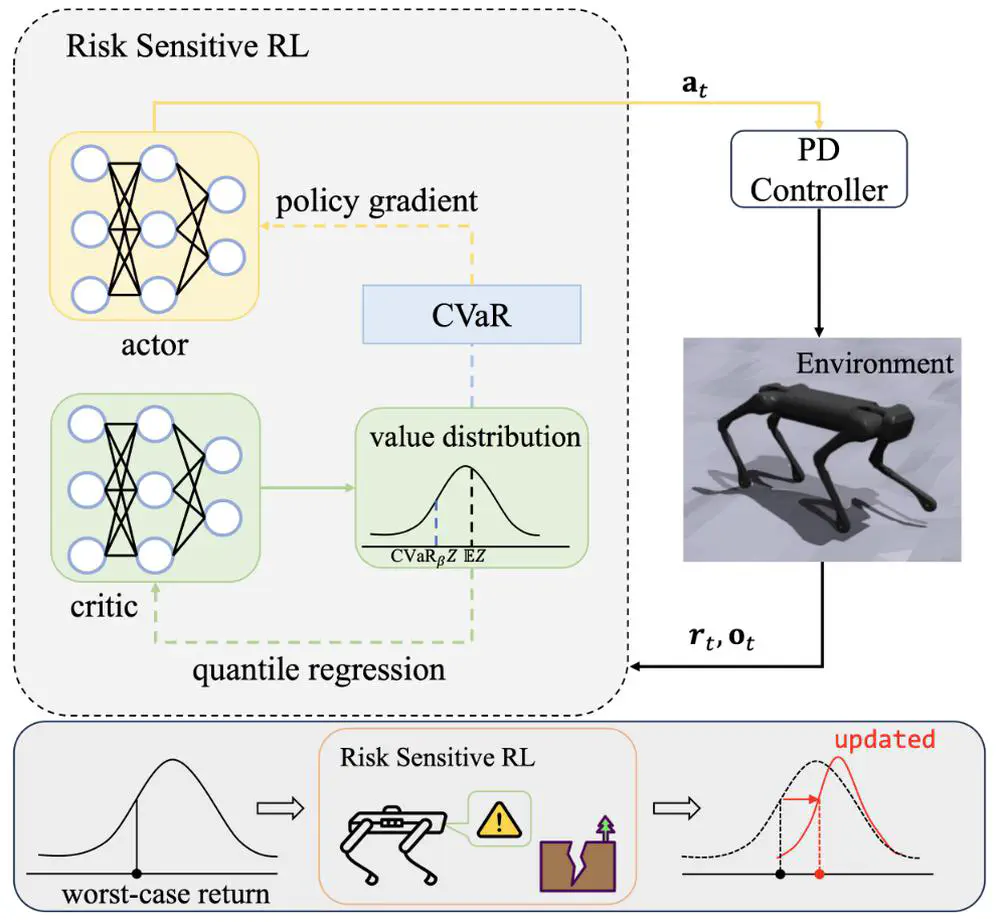
In IEEE International Conference on Robotics and Automation (ICRA), 2024 Oral
We consider a novel risk-sensitive perspective to enhance the robustness of legged locomotion.
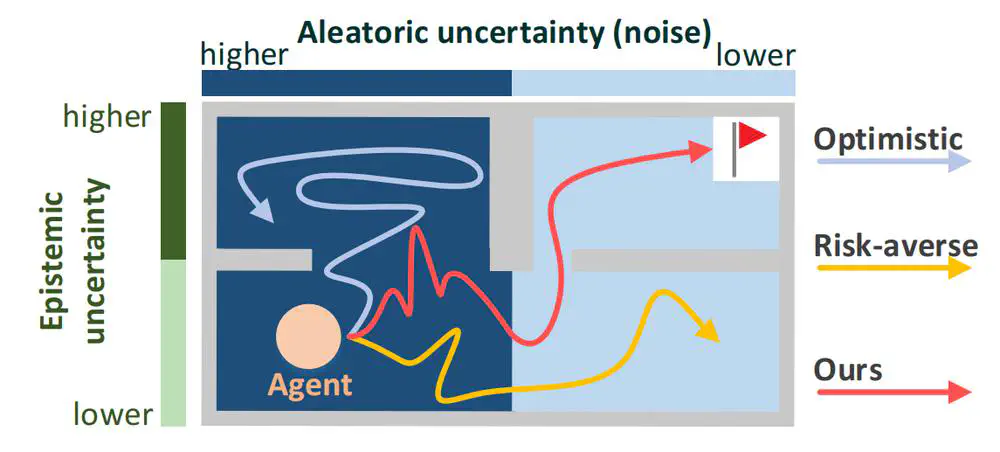
In AAAI Conference on Artificial Intelligence (AAAI), 2024
We propose Optimistic Value Distribution Explorer (OVD-Explorer) to achieve a noise-aware optimistic exploration for continuous control.
In Neural Information Processing Systems (NeurIPS), 2024
We introduce a novel framework that leverages a unified discrete diffusion to combine generative pre-training on human videos and policy fine-tuning on a small number of action-labeled robot videos.
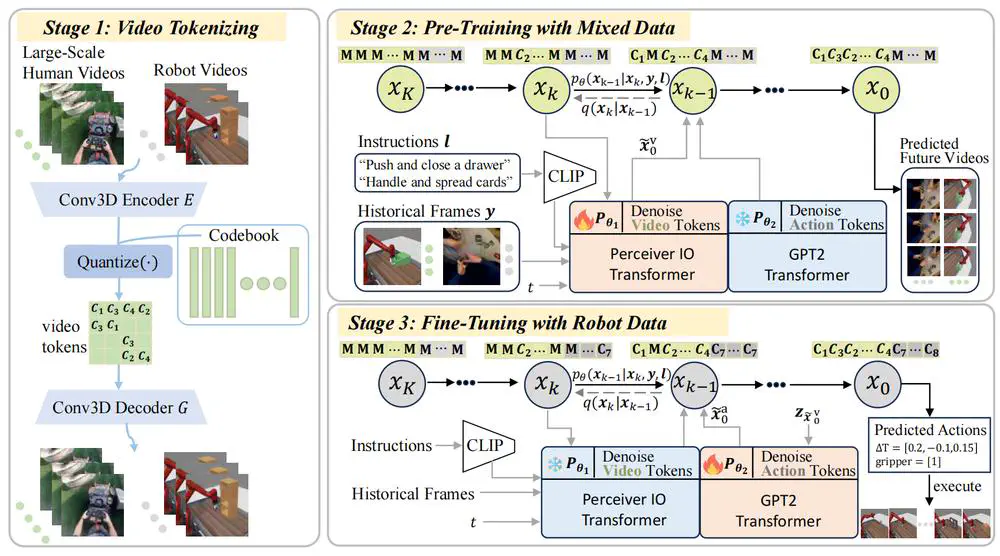
In Journal of Artificial Intelligence Research (JAIR), 2023
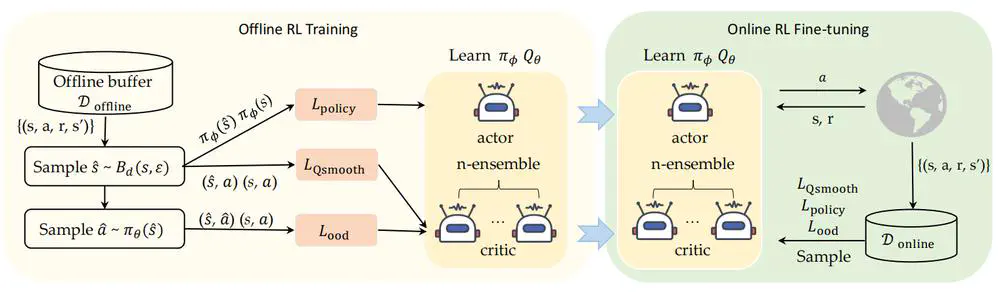
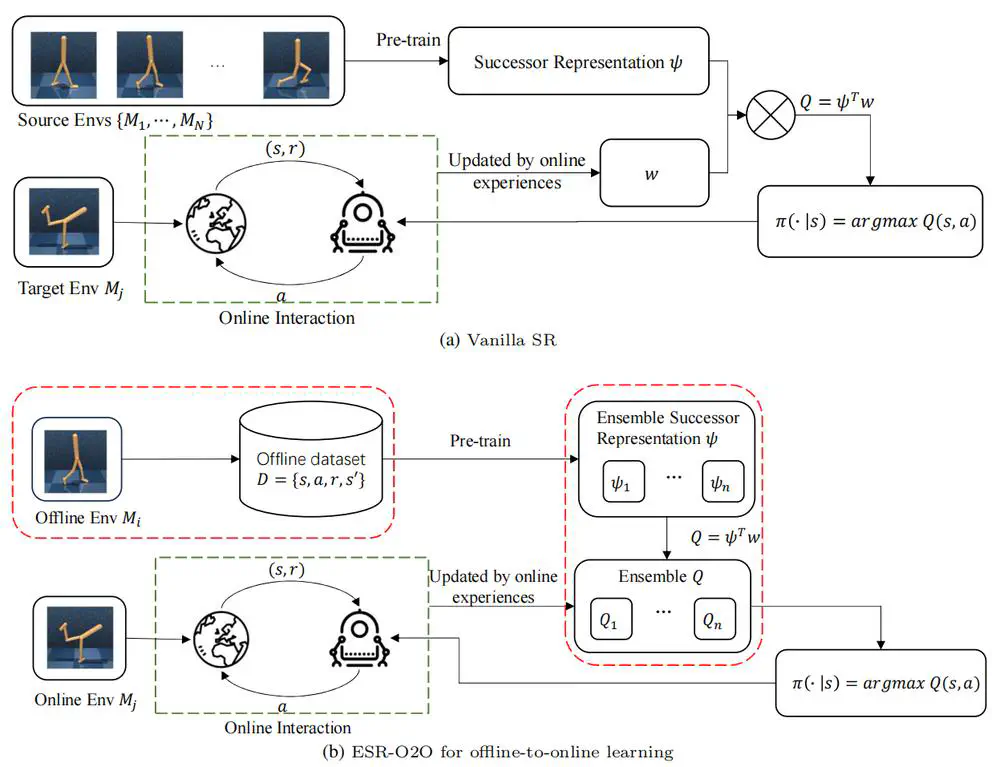
We propose the Robust Offline-to-Online (RO2O) algorithm, designed to enhance offline policies through uncertainty and smoothness, and to mitigate the performance drop in online adaptation.
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025
We present a framework called Selective Myopic bEhavior Control~(SMEC), which results from the insight that the short-term behaviors of prior policies are sharable across tasks.
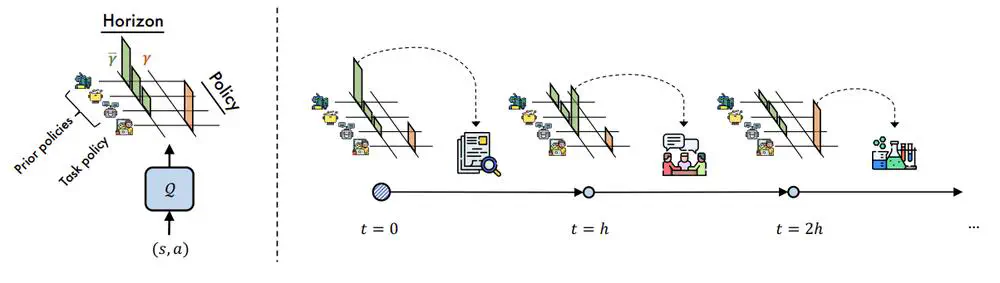

In Neural Information Processing Systems (NeurIPS), 2023
We aim to investigate the effectiveness of a single diffusion model in modeling large-scale multi-task offline data, which can be challenging due to diverse and multimodal data distribution.
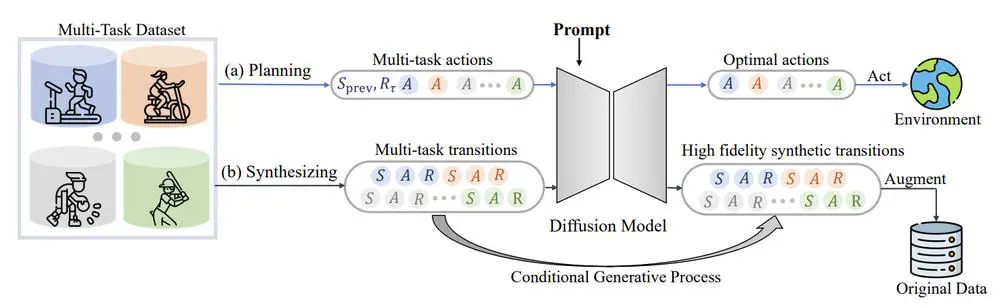
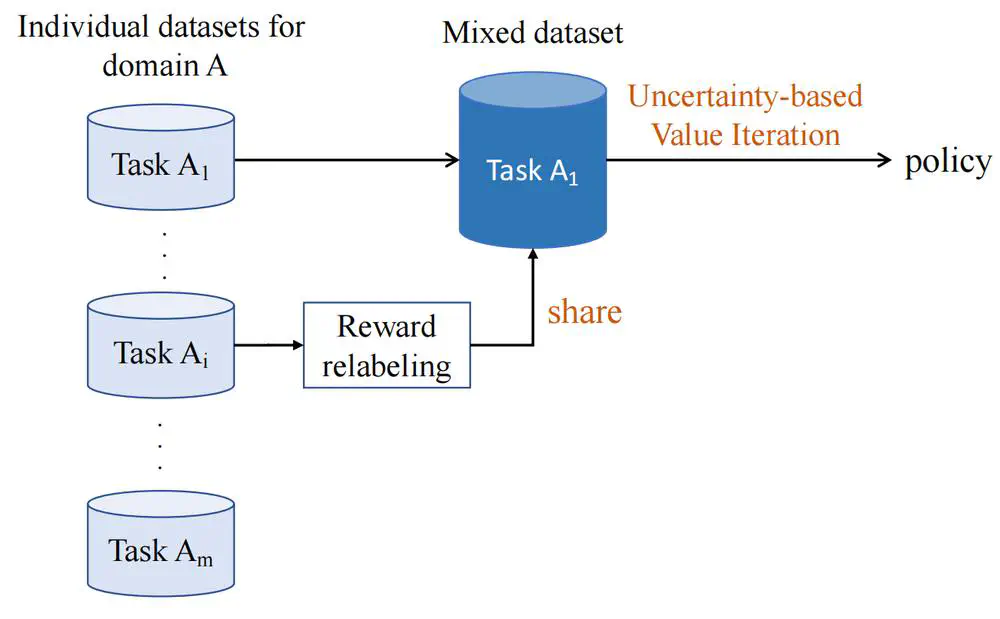
In International Conference on Machine Learning (ICML), 2025
We develop a versatile diffusion planner that can leverage large-scale inferior data that contains task-agnostic sub-optimal trajectories, with the ability to fast adapt to specific tasks.
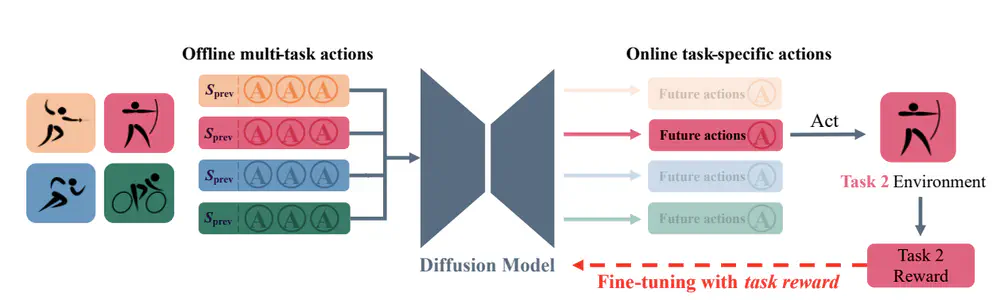
In Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2024
We introduce ODRL, the first benchmark tailored for evaluating off-dynamics RL methods where one needs to transfer policies across different domains with dynamics mismatch.
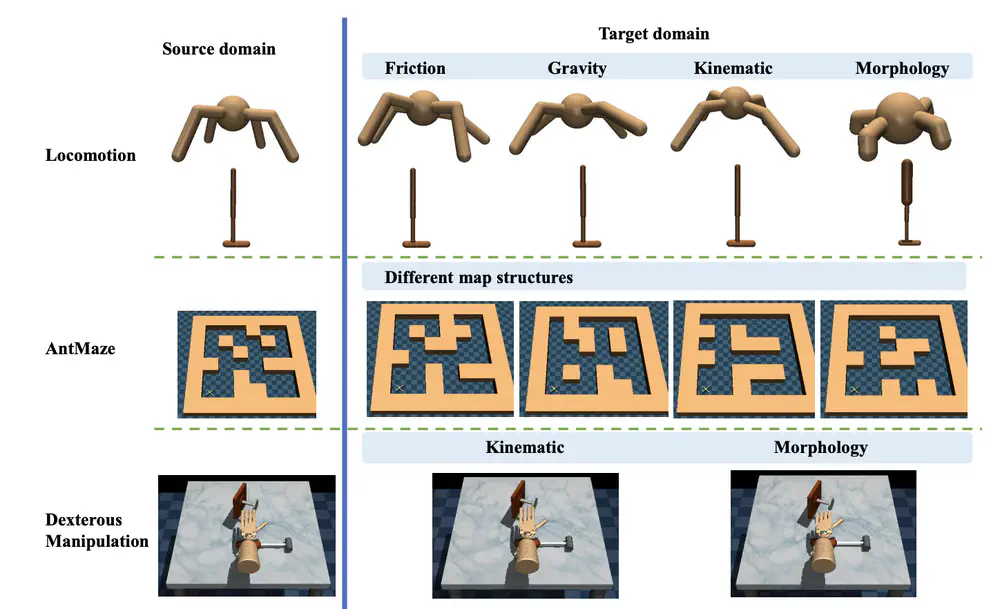
In International Conference on Machine Learning (ICML), 2023
We propose a novel unsupervised skill discovery method through contrastive learning among behaviors, which makes the agent produce similar behaviors for the same skill and diverse behaviors for different skills.
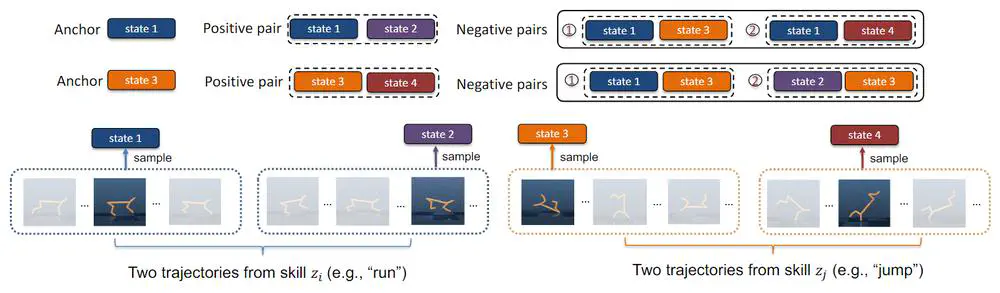
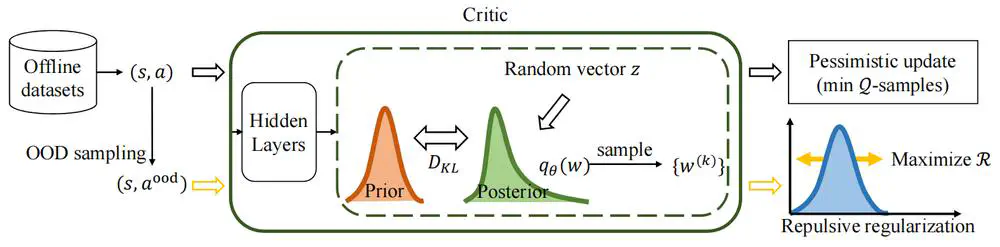
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023
We propose falSe COrrelation REduction (SCORE) for offline RL, a practically effective and theoretically provable algorithm.
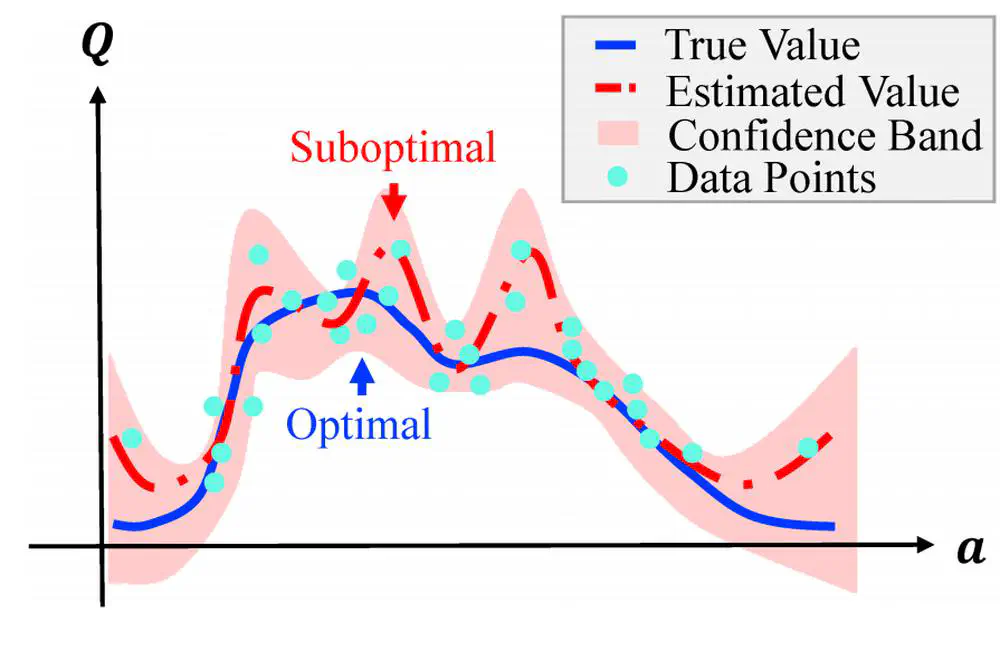


In Neural Information Processing Systems (NeurIPS), 2025
We propose a physics-based humanoid control framework, aiming to master highly-dynamic human behaviors such as Kungfu and dancing through multi-steps motion processing and adaptive motion tracking.

In Neural Information Processing Systems (NeurIPS), 2025
we propose HumanoidGen, an automated task creation and demonstration collection framework that leverages atomic dexterous operations and LLM reasoning to generate relational constraints.

In Neural Information Processing Systems (NeurIPS), 2025
We propose Diffusion-Inspired Multi-Agent world model (DIMA), a novel framework for multi-agent reinforcement learning that leverages diffusion models to reduce modeling complexity and improve sample efficiency.
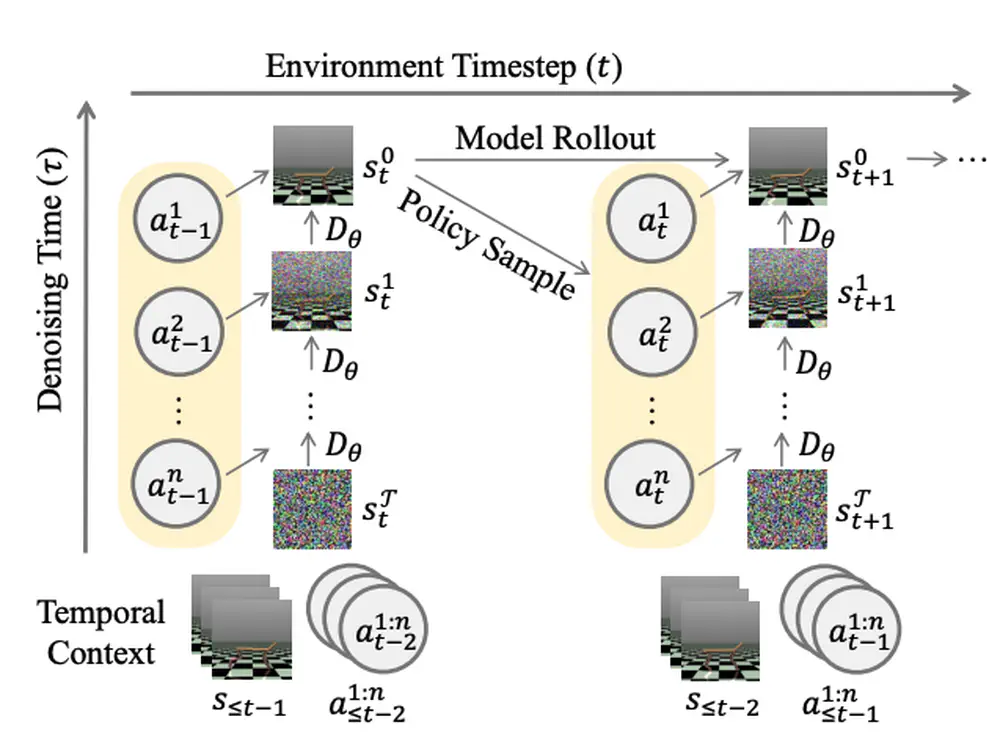
In Neural Information Processing Systems (NeurIPS), 2025
We propose Adversarial Locomotion and Motion Imitation (ALMI) for humanoid robots, which serves as a novel framework for loco-manipulation tasks, enabling adversarial policy learning between upper and lower body.
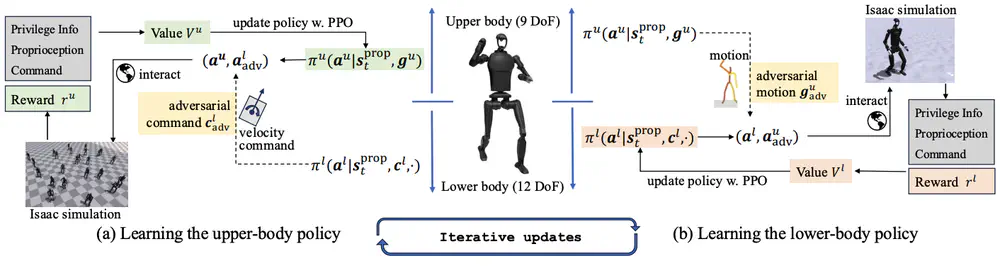
In Neural Information Processing Systems (NeurIPS), 2025
We decompose the reward value in RLHF into two independent components that consists prompt-free reward and prompt-related reward, and propose a new reward learning algorithm by prioritizing data samples based on their prompt-free reward values.
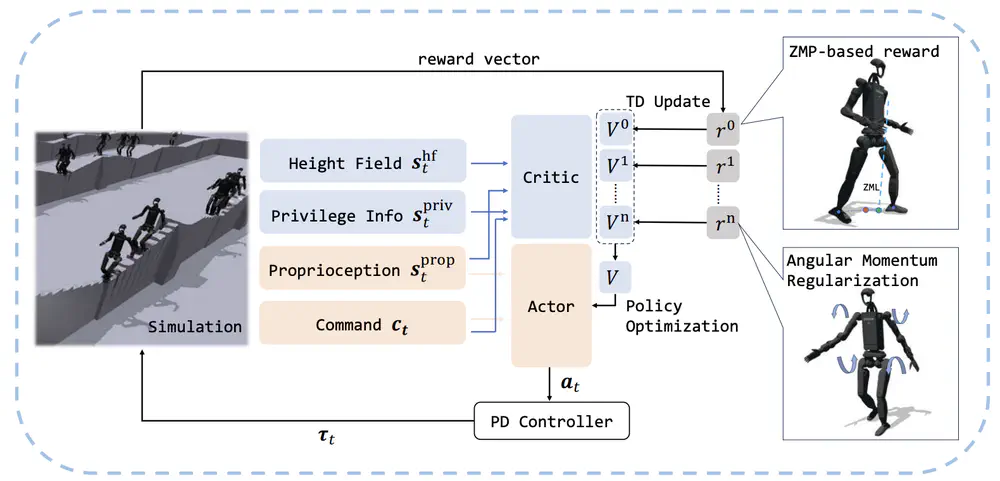
In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025
we propose a novel whole-body locomotion algorithm based on dynamic balance and Reinforcement Learning (RL) that enables humanoid robots to traverse extreme terrains, particularly narrow pathways and unexpected obstacles, using only proprioception.
In Journal of the American Statistical Association (JASA), 2025
This paper proposes an offline Wasserstein-based approach to estimate the joint distribution of multivariate discounted cumulative rewards, establishes finite sample error bounds in the batch setting, and demonstrates its superior performance through extensive numerical studies.

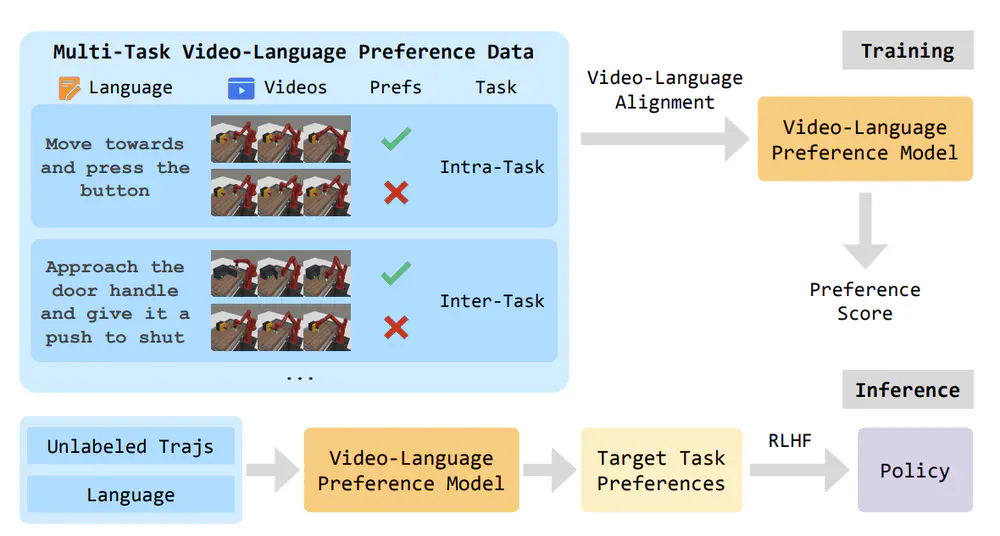
In Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025
we propose a novel Vision-Language Preference learning framework that learns a vision-language preference model to provide preference feedback for embodied manipulation tasks.
In Annual Conference on Robot Learning (CORL), 2024 Oral
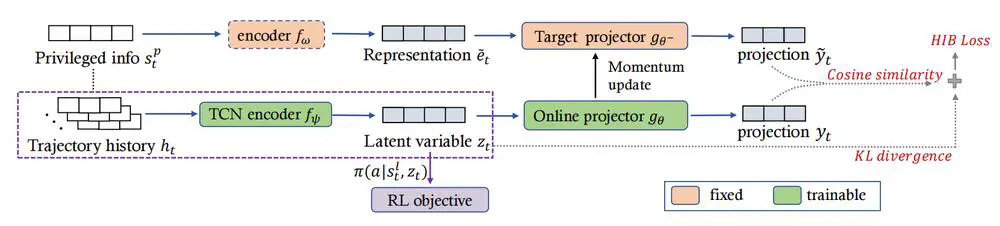
We propose a novel single-stage privileged knowledge distillation method called the Historical Information Bottleneck (HIB) to narrow the sim-to-real gap for legged locomotion.
In Neural Information Processing Systems (NeurIPS), 2022 Spotlight
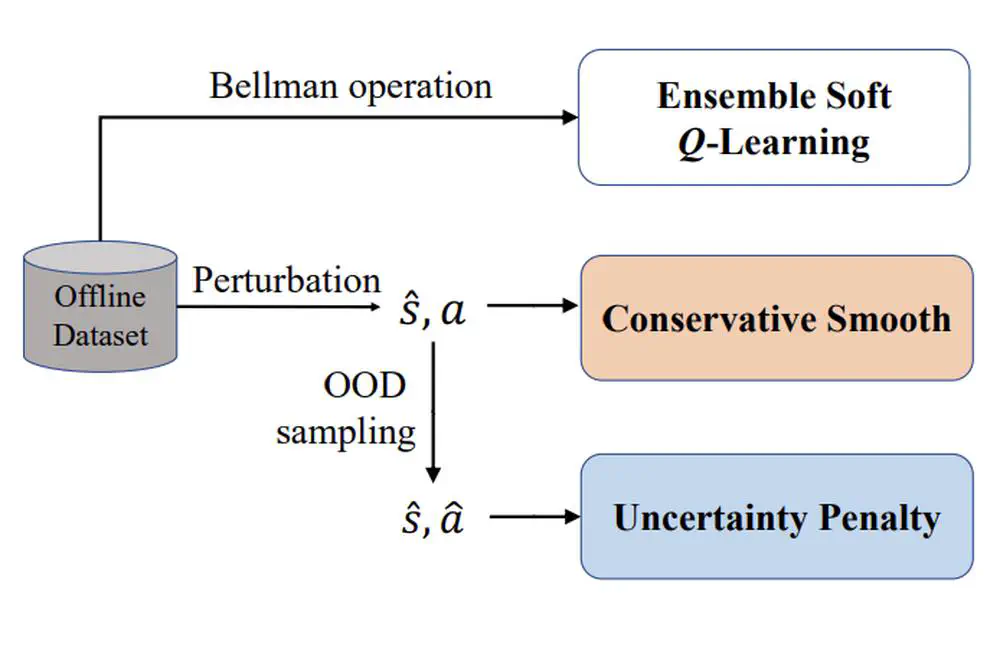
We propose Robust Offline Reinforcement Learning (RORL) with a novel conservative smoothing technique.
IEEE Transactions on Systems, Man, and Cybernetics: Systems. 2022
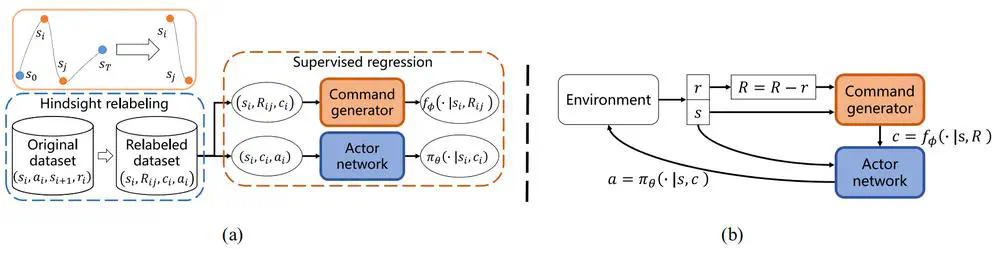
We present an offline RL algorithm that combines hindsight relabeling and supervised regression to predict actions without oracle information.
In International Conference on Machine Learning (ICML), 2022 Spotlight
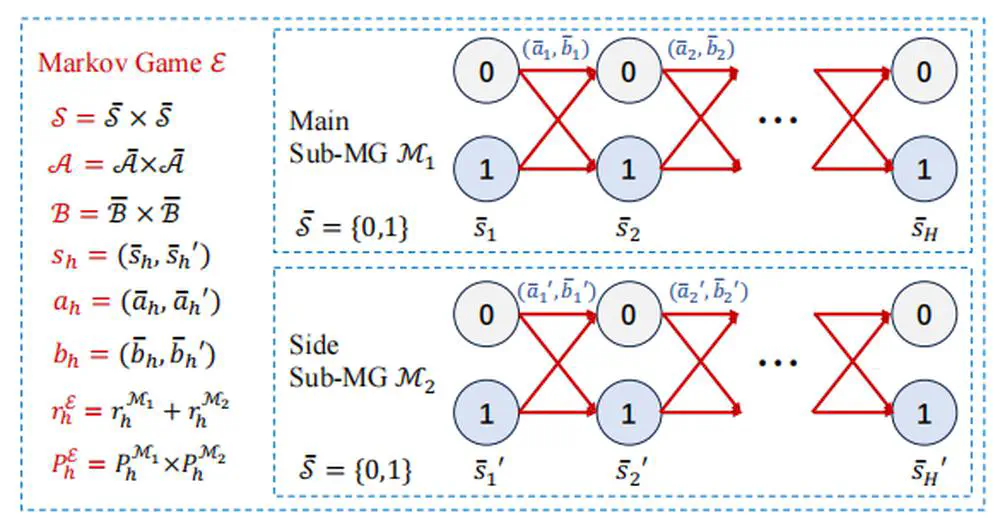
We study how RL can be empowered by contrastive learning in a class of Markov decision processes (MDPs) and Markov games (MGs) with low-rank transitions. For both models, we propose to extract the correct feature representations of the low-rank model by minimizing a contrastive loss.
IEEE Transactions on Neural Networks and Learning Systems, 2022
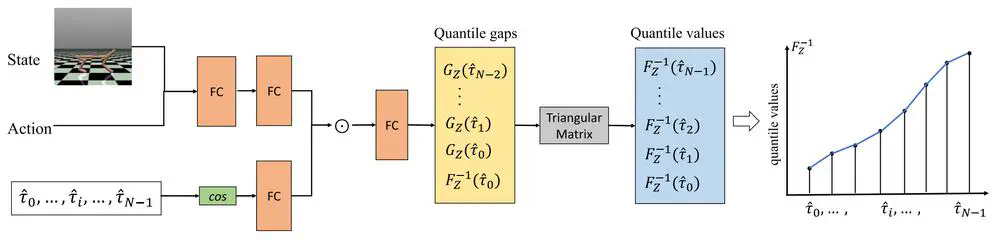
We propose monotonic quantile network (MQN) with conservative quantile regression (CQR) for risk-averse policy learning.
IEEE Transactions on Neural Networks and Learning Systems, 2022
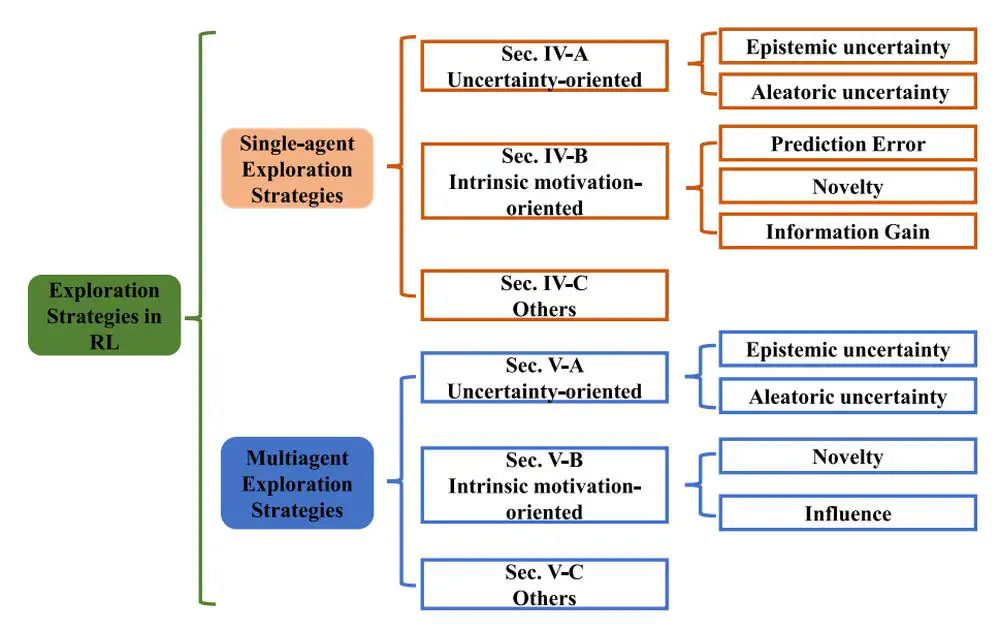
We conduct a comprehensive survey on existing exploration methods for both single-agent RL and multiagent RL.
International Conference on Learning Representations (ICLR), 2022 Spotlight
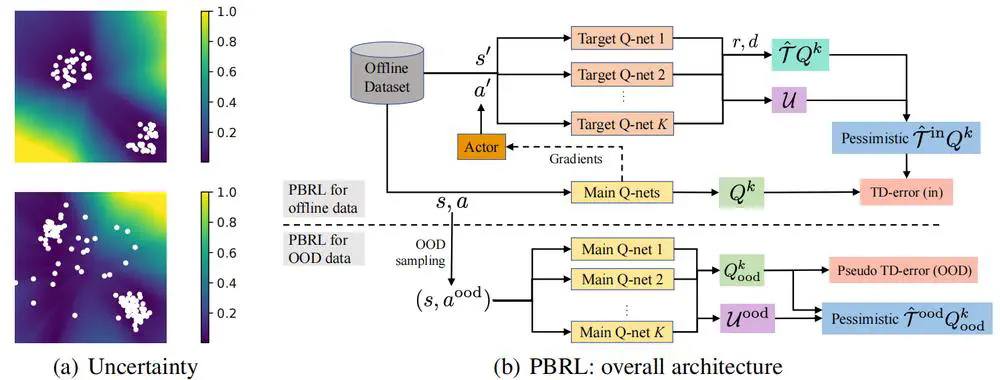
We propose Pessimistic Bootstrapping for offline RL (PBRL), a purely uncertainty-driven offline algorithm without explicit policy constraints.
In Neural Information Processing Systems (NeurIPS), 2021
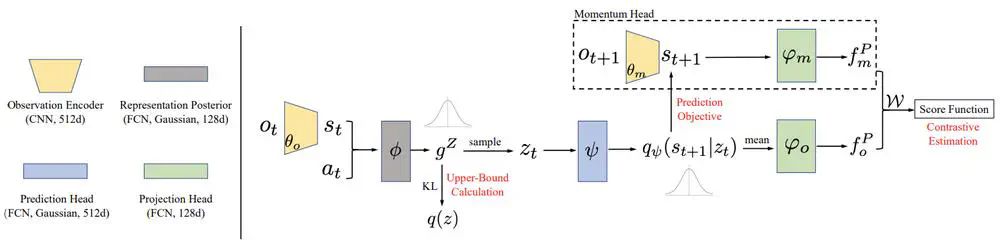
We propose a Dynamic Bottleneck (DB) model, which attains a dynamics-relevant representation based on the information-bottleneck principle.
In International Conference on Machine Learning (ICML), 2021 Spotlight
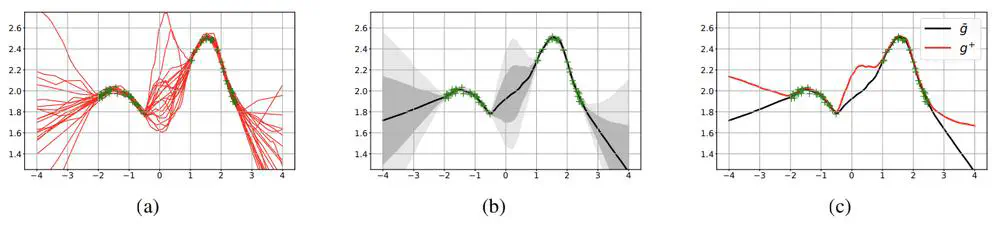
We propose a principled exploration method for DRL through Optimistic Bootstrapping and Backward Induction (OB2I).
IEEE Transactions on Neural Networks and Learning Systems, 2021
We propose a variational dynamic model based on the conditional variational inference to model the multimodality and stochasticity.
Journal of Computer Research and Development (in Chinese), 2019
We propose an active sampling method based on TD-error adaptive correction in order to solve sample efficiency problem in deep Q-learning.
In Transactions on Machine Learning Research (TMLR), 2025
we propose a novel world model for MARL that learns decentralized local dynamics for scalability, combined with a centralized representation aggregation from all agents.