Article-Journal
Journal of Computer Research and Development (in Chinese), 2019
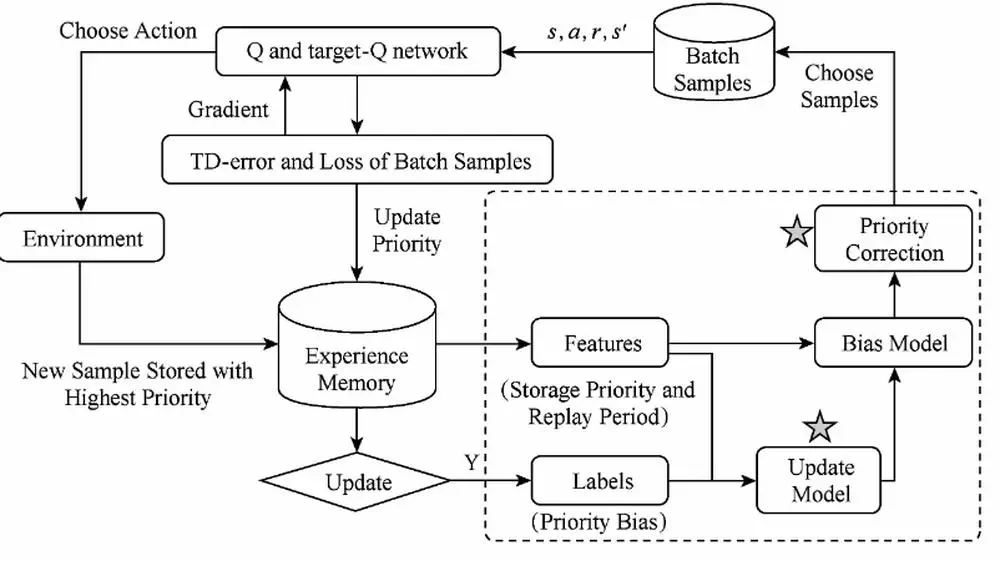
We propose an active sampling method based on TD-error adaptive correction in order to solve sample efficiency problem in deep Q-learning.
Knowledge-Based Systems (KBS), 2020
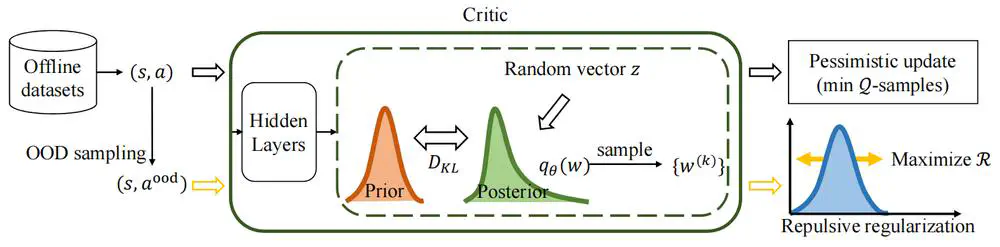
This paper describes a method of obtaining more accurate estimated action values for CDRL using adaptive bounds.
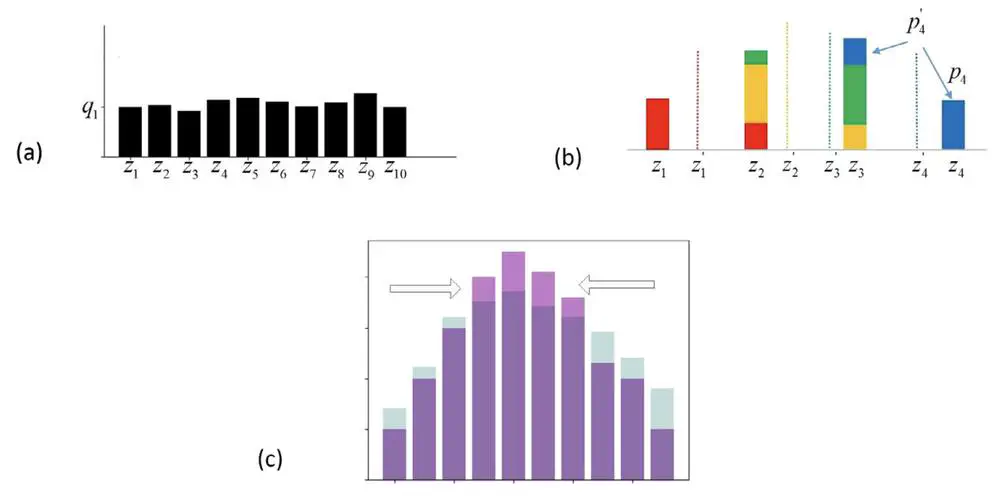
Knowledge-Based Systems (KBS), 2020
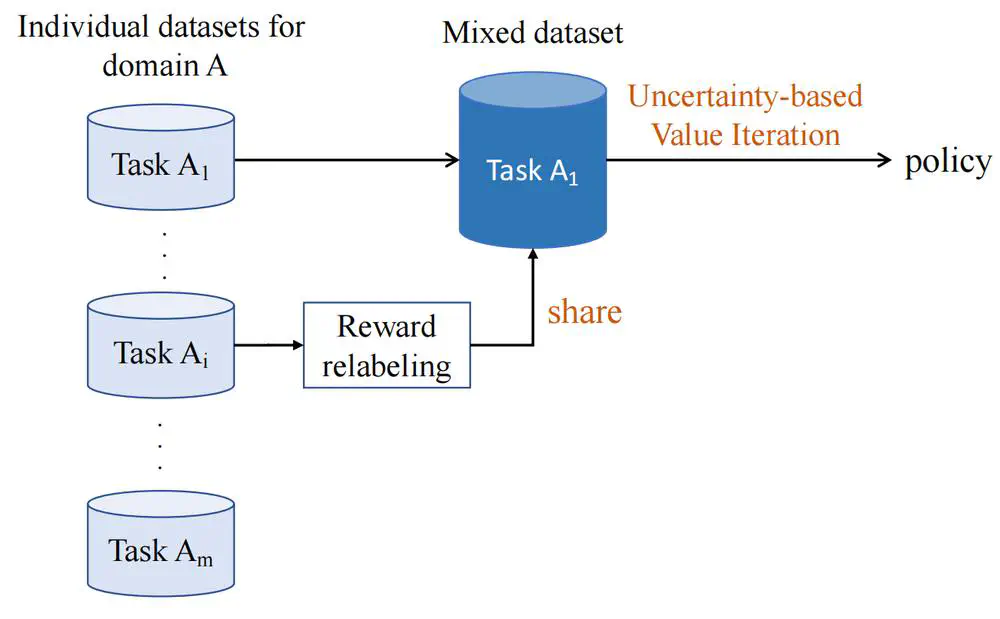
We propose a novel prioritized hindsight model for multi-goal RL in which the agent is provided with more valuable goals, as measured by the expected temporal-difference (TD) error.
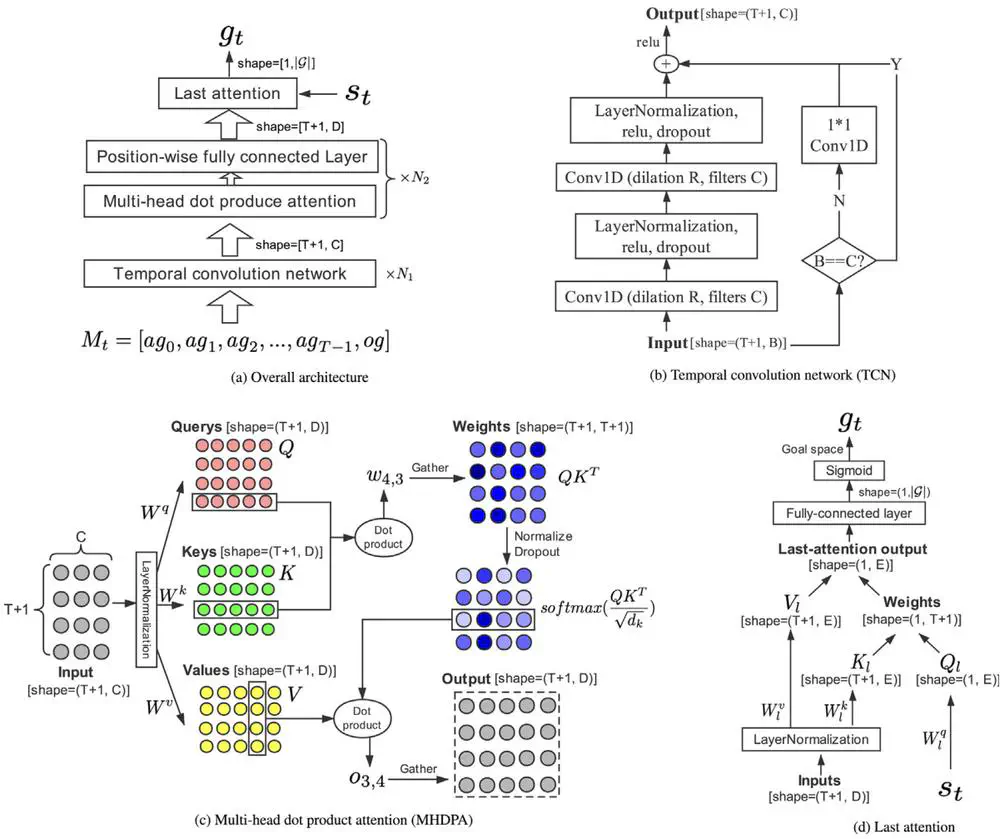
IEEE Transactions on Neural Networks and Learning Systems, 2021
We propose a variational dynamic model based on the conditional variational inference to model the multimodality and stochasticity.
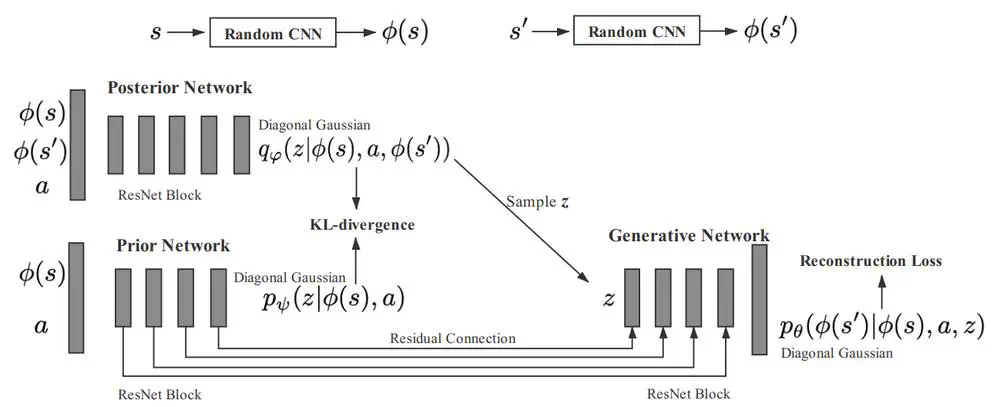
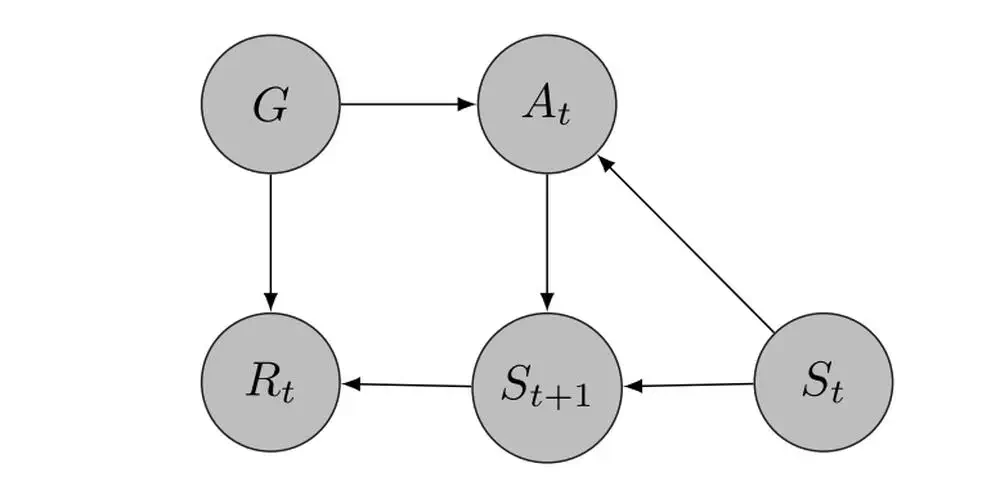
IEEE Transactions on Cybernetics, 2021
We analyze the hindsight bias due to this use of hindsight goals and propose the bias-corrected HER (BHER), an efficient algorithm that corrects the hindsight bias in training.
IEEE Transactions on Neural Networks and Learning Systems, 2022
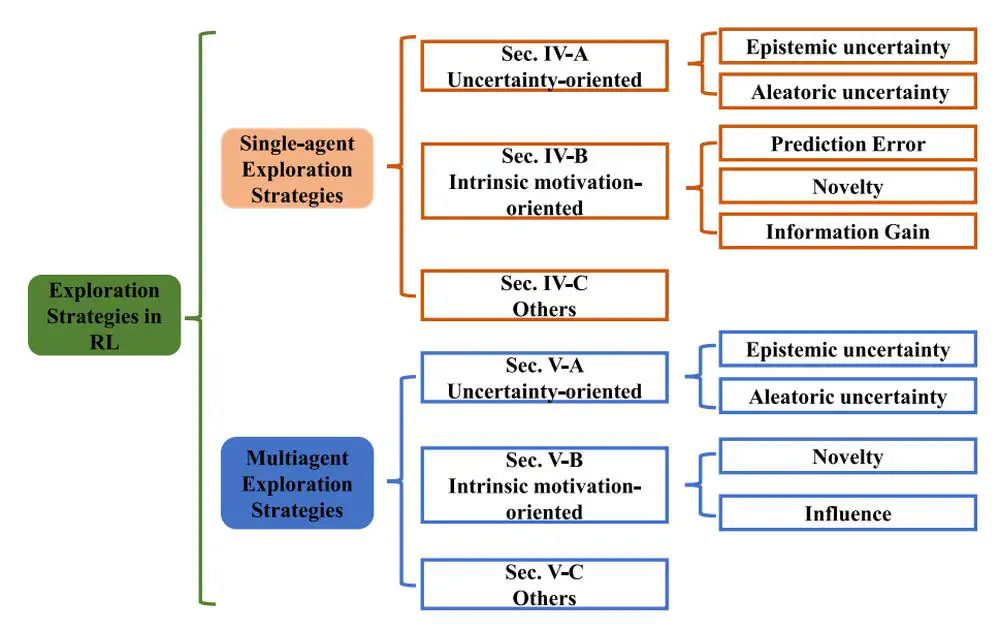
We conduct a comprehensive survey on existing exploration methods for both single-agent RL and multiagent RL.
IEEE Transactions on Neural Networks and Learning Systems, 2022
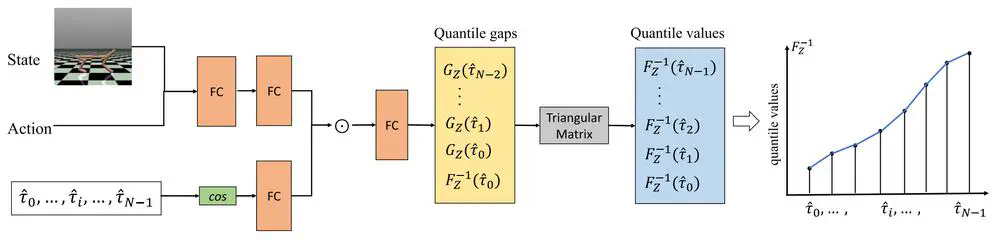
We propose monotonic quantile network (MQN) with conservative quantile regression (CQR) for risk-averse policy learning.
IEEE Transactions on Systems, Man, and Cybernetics: Systems. 2022
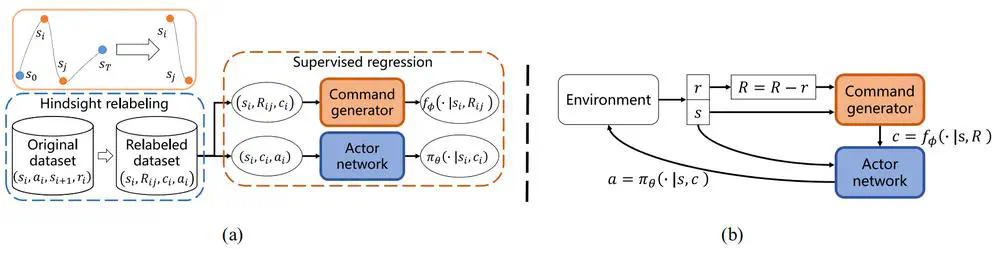
We present an offline RL algorithm that combines hindsight relabeling and supervised regression to predict actions without oracle information.