Article-Journal
In SCIENCE CHINA Information Sciences, 2023
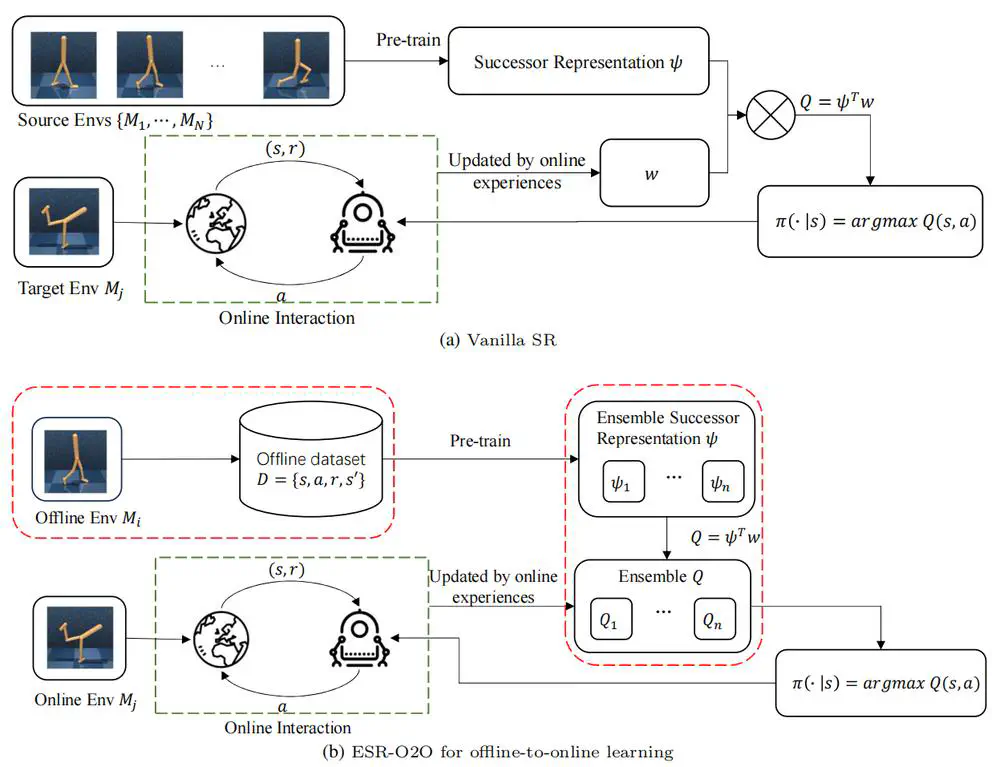
Our work builds upon the investigation of successor representations for task generalization in online RL and extends the framework to incorporate offline-to-online learning.
In Journal of Artificial Intelligence Research (JAIR), 2023
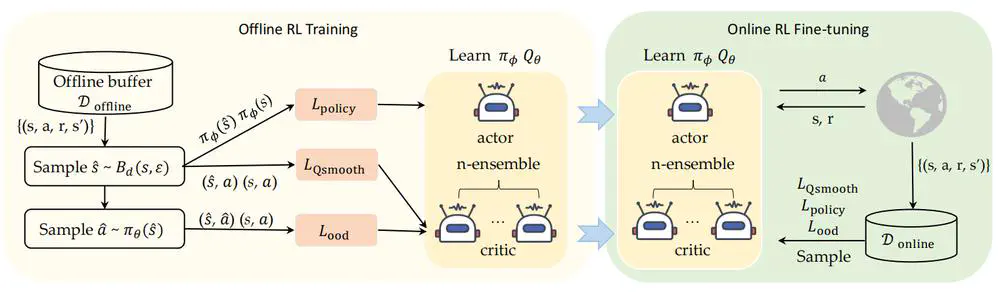
We propose the Robust Offline-to-Online (RO2O) algorithm, designed to enhance offline policies through uncertainty and smoothness, and to mitigate the performance drop in online adaptation.
Neural Networks, 2024
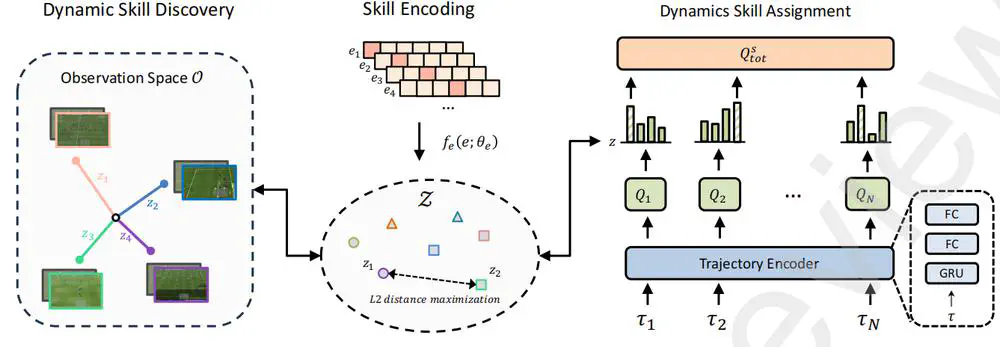
We propose a novel Dynamic Skill Learning (DSL) framework to enable more effective adaptation and collaboration in complex tasks.
In Transactions on Machine Learning Research (TMLR), 2025
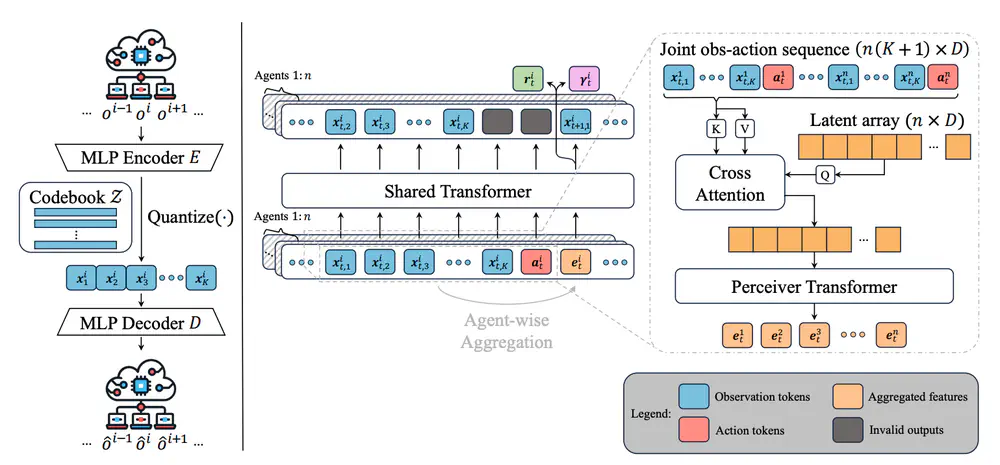
we propose a novel world model for MARL that learns decentralized local dynamics for scalability, combined with a centralized representation aggregation from all agents.

In Journal of the American Statistical Association (JASA), 2025
This paper proposes an offline Wasserstein-based approach to estimate the joint distribution of multivariate discounted cumulative rewards, establishes finite sample error bounds in the batch setting, and demonstrates its superior performance through extensive numerical studies.
