Conference
In IEEE International Conference on Robotics and Automation (ICRA), 2024 Oral
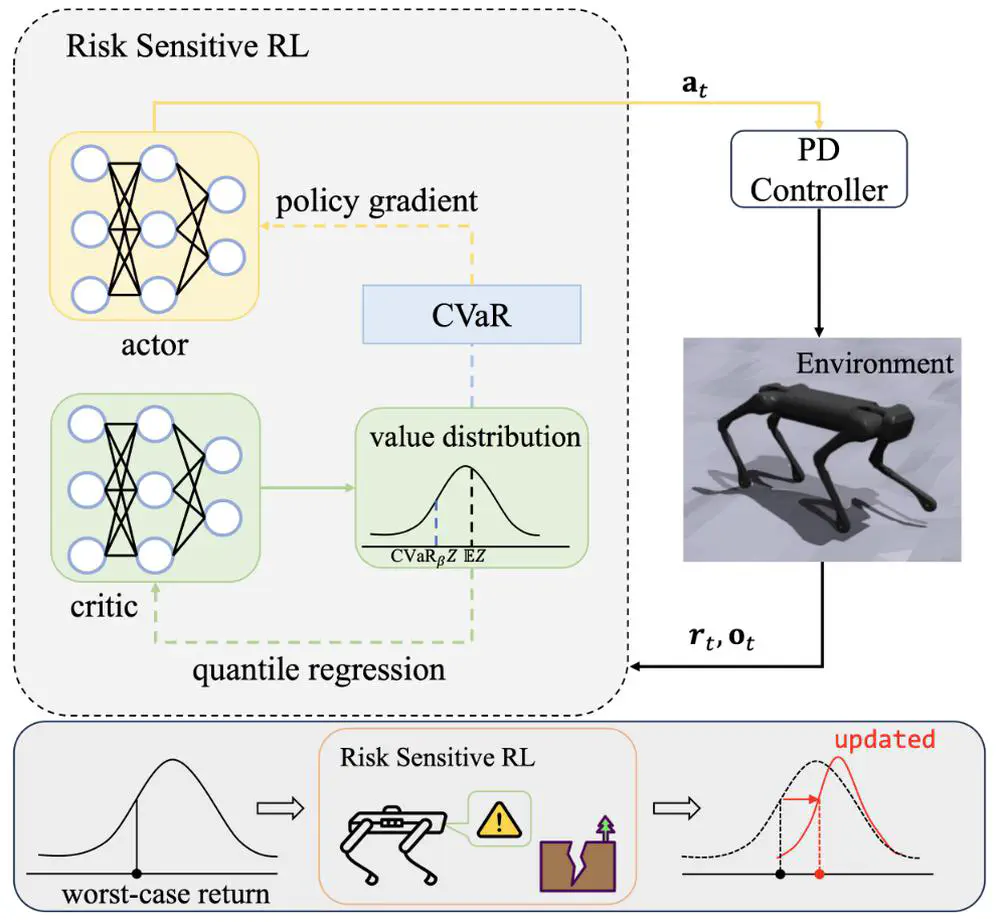
We consider a novel risk-sensitive perspective to enhance the robustness of legged locomotion.
In International Conference on Machine Learning (ICML), 2024
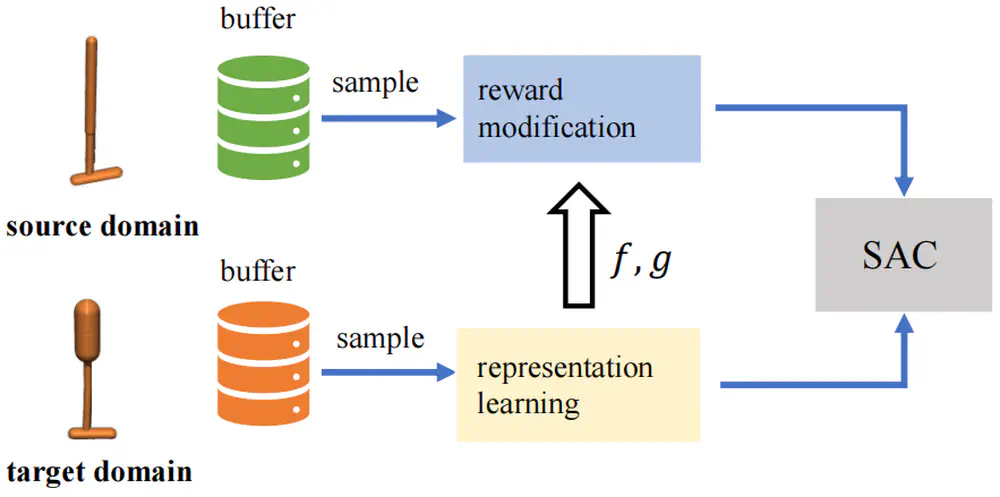
We consider dynamics adaptation settings where there exists dynamics mismatch between the source domain and the target domain, and one can get access to sufficient source domain data, while can only have limited interactions with the target domain.
In International Conference on Machine Learning (ICML), 2024
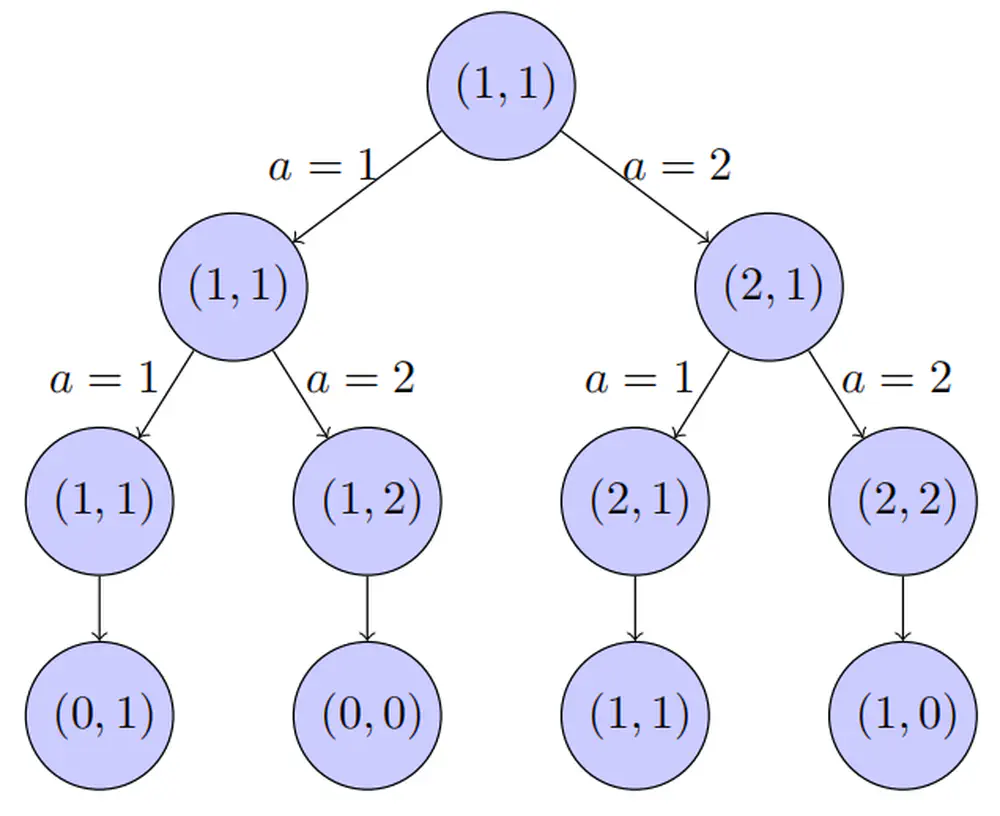
We construct an example to show the information-theoretical improvement in sample efficiency achieved by goal relabeling and develop an RL algorithm called GOALIVE.
In International Conference on Machine Learning (ICML), 2024
We propose SAM-E, a novel architecture for robot manipulation by leveraging a vision-foundation model for generalizable scene understanding and sequence imitation for long-term action reasoning.
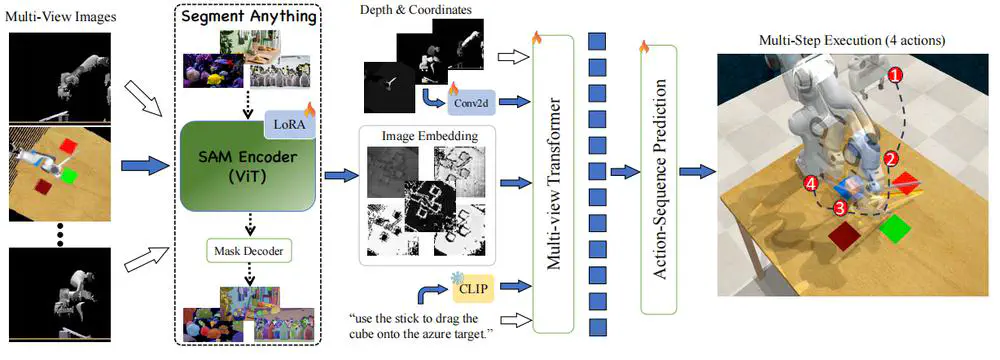
In International Conference on Machine Learning (ICML), 2024
We propose a novel representation-based approach to measure the domain gap, where the representation is learned through a contrastive objective by sampling transitions from different domains.

In International Conference on Machine Learning (ICML), 2024
We propose a novel unsupervised RL framework via an ensemble of skills, where each skill performs partition exploration based on the state prototypes.
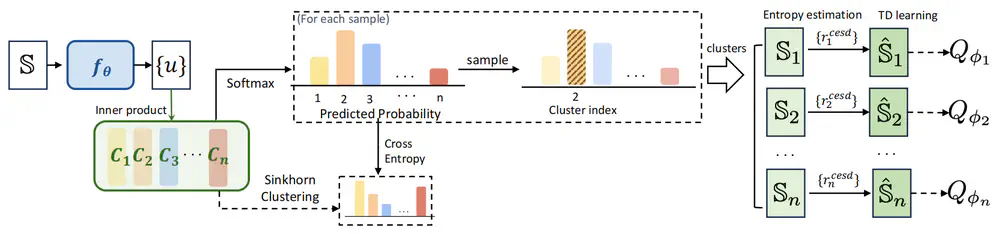
In European Conference on Artificial Intelligence (ECAI), 2024
We propose a novel dynamic policy constraint that restricts the learned policy on the samples generated by the exponentional moving average of previously learned policies for offline RL.
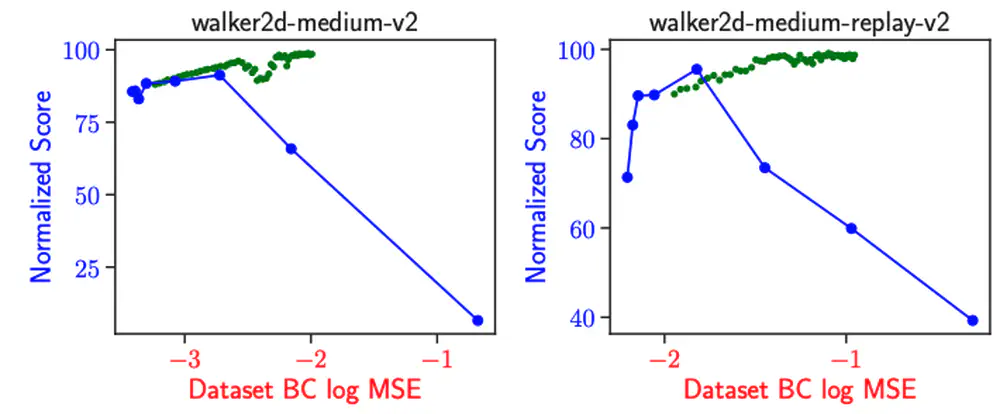
In Annual Conference on Robot Learning (CORL), 2024 Oral
We propose a novel single-stage privileged knowledge distillation method called the Historical Information Bottleneck (HIB) to narrow the sim-to-real gap for legged locomotion.
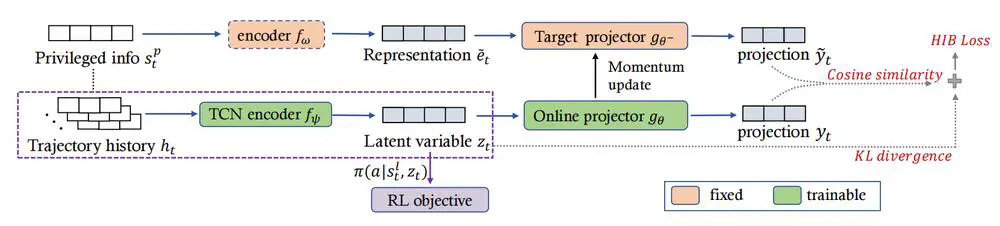
In Neural Information Processing Systems (NeurIPS), 2024
We introduce a novel framework that leverages a unified discrete diffusion to combine generative pre-training on human videos and policy fine-tuning on a small number of action-labeled robot videos.
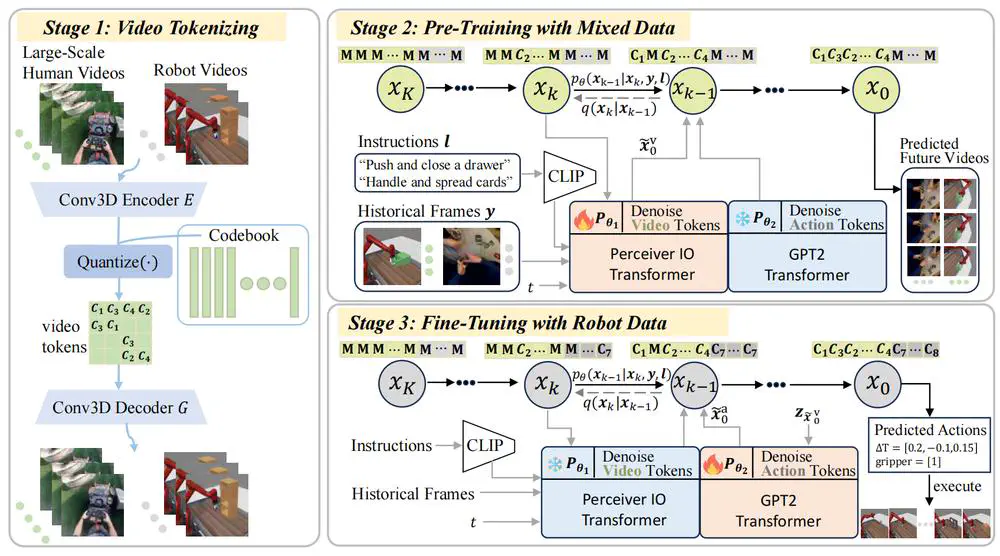
In Neural Information Processing Systems (NeurIPS), 2024
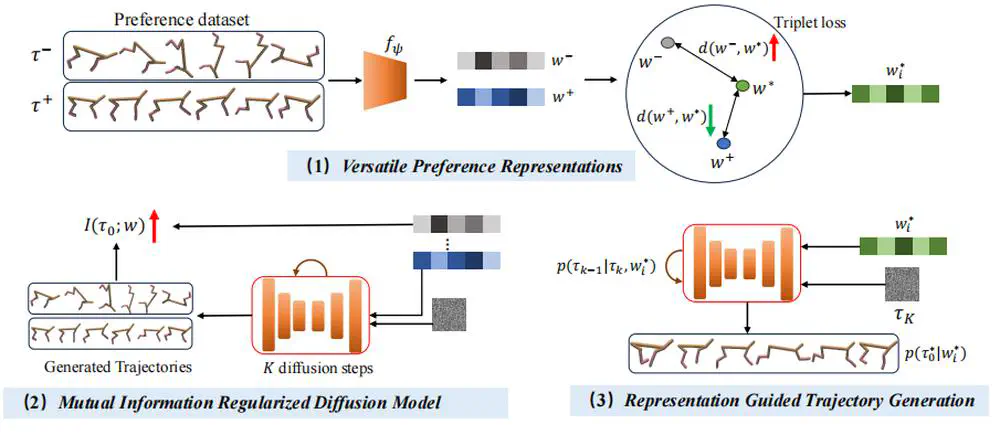
We adopt multi-task preferences as a unified condition for both single- and multi-task decision-making, and propose preference representations aligned with preference labels.