Conference
In Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2024
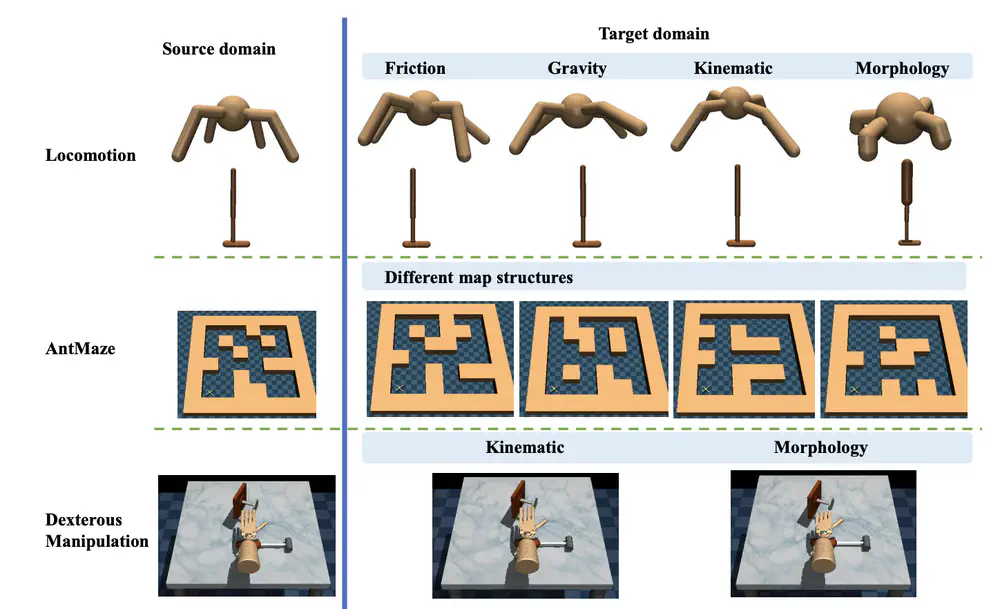
We introduce ODRL, the first benchmark tailored for evaluating off-dynamics RL methods where one needs to transfer policies across different domains with dynamics mismatch.
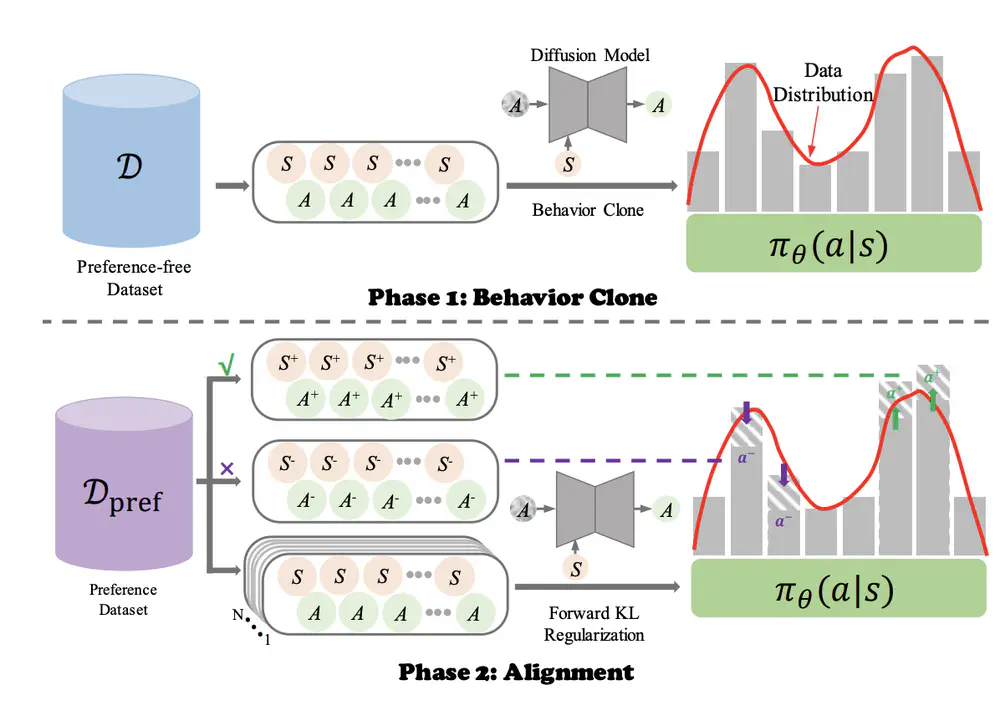
In AAAI Conference on Artificial Intelligence (AAAI), 2025
We propose Forward KL regularized Preference optimization for aligning Diffusion policies to align the diffusion policy with preferences, learning to align the policy output with human intents in various tasks.
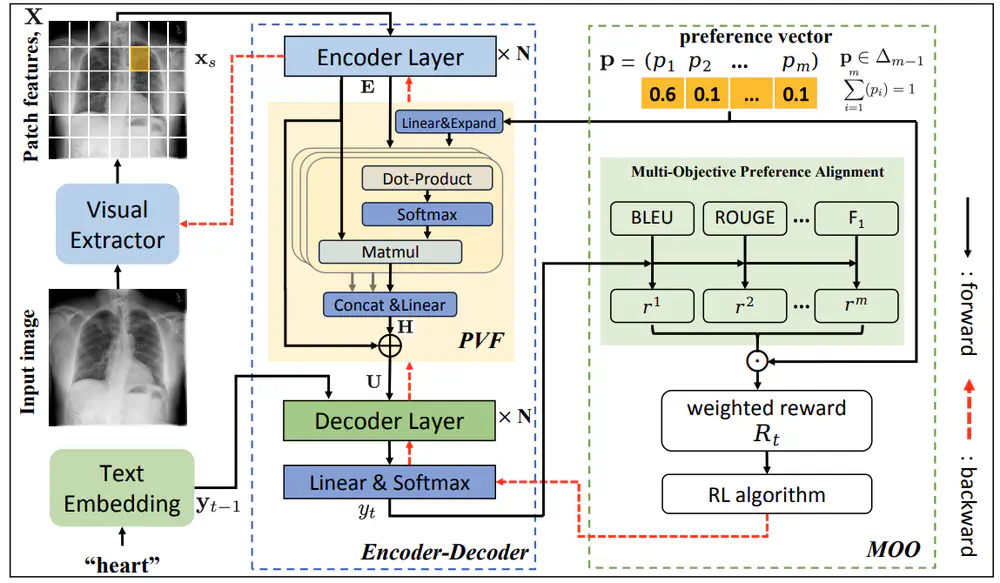
In AAAI Conference on Artificial Intelligence (AAAI), 2025
We propose a new radiology report generation method that aligns the pre-trained model with multiple human preferences via preference-guided multi-objective optimization reinforcement learning.
In International Conference on Learning Representations (ICLR), 2025
We introduce ExpoComm, a scalable communication protocol that leverages exponential topologies for efficient information dissemination among many agents in large-scale multi-agent reinforcement learning.
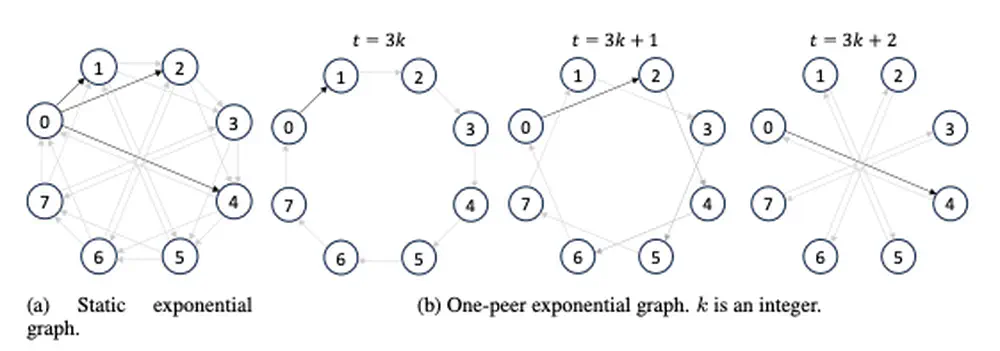
In International Conference on Learning Representations (ICLR), 2025
We propose a novel framework that generalizes demonstrations to establish critic-regularized grounding and optimization in the long-term planning of LLMs.
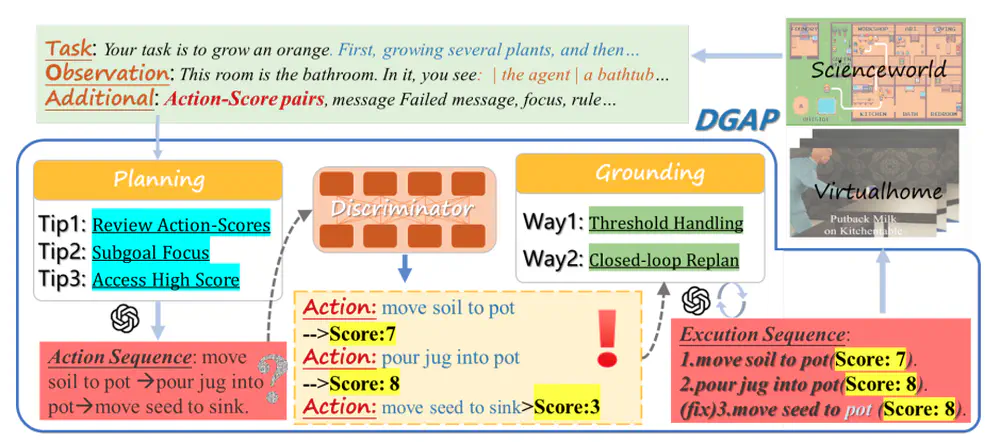
In International Conference on Learning Representations (ICLR), 2025 Spotlight
We propose count-based online preference optimization for LLM alignment that leverages coin-flip counting to encourage exploration in online RLHF.
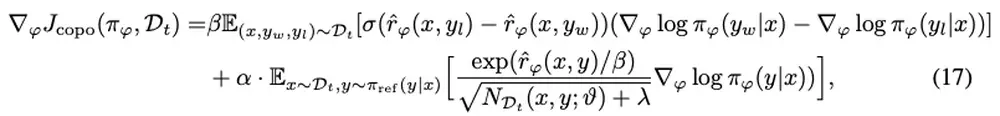
In International Conference on Machine Learning (ICML), 2025
We develop a versatile diffusion planner that can leverage large-scale inferior data that contains task-agnostic sub-optimal trajectories, with the ability to fast adapt to specific tasks.
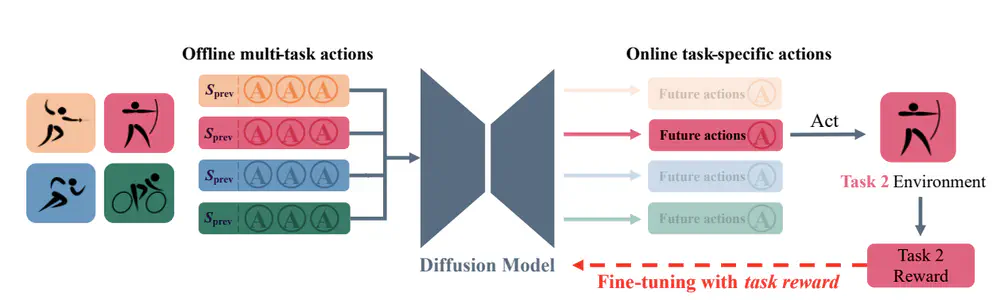
In Annual Meeting of the Association for Computational Linguistics (ACL), 2025
We propose a novel framework for multi-agent collaboration that introduces Reinforced Advantage feedback (ReAd) for efficient self-refinement of plans.
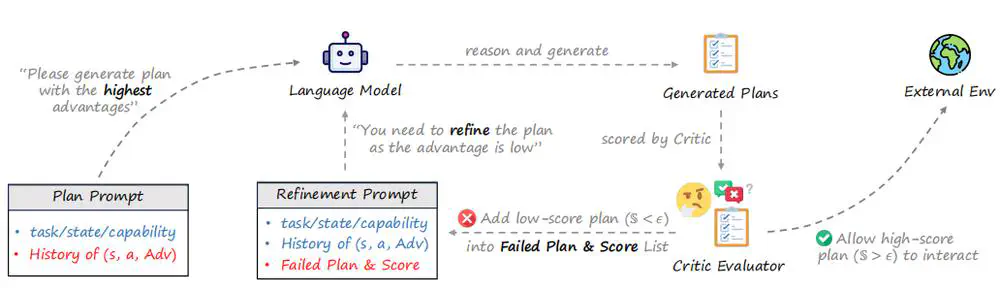
In Annual Meeting of the Association for Computational Linguistics (ACL), 2025
We propose an online iterative self-alignment method for radiology report generation that iteratively generates unlimited preference data and automatically aligns with radiologists’ multiple objectives.
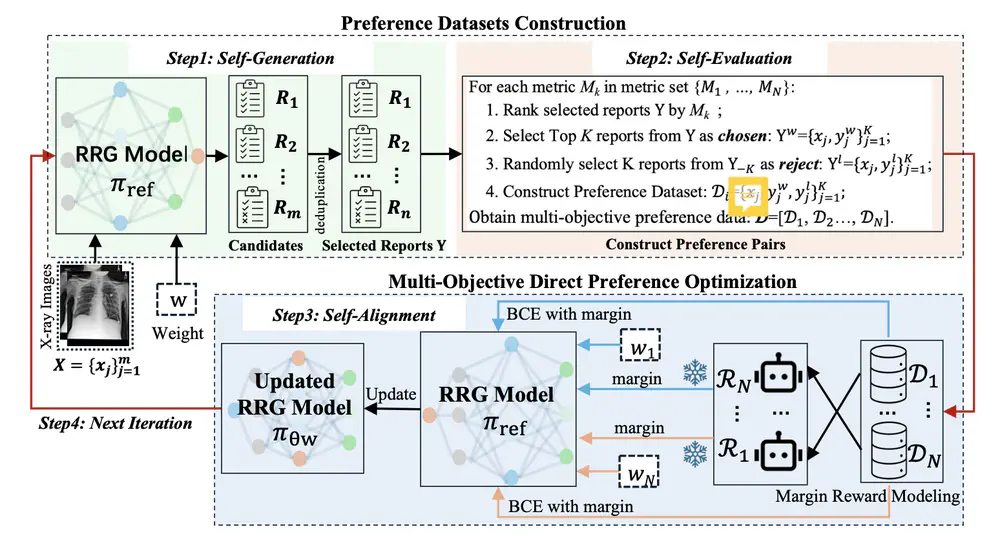
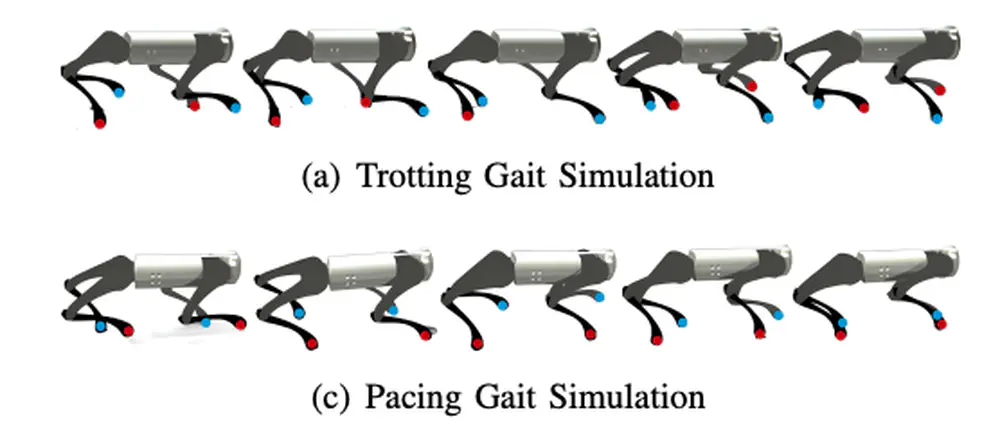
In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025
We develop a learning framework combining offline diffusion planner and online preference alignment with weak preference labeling for legged locomotion control.