Chenjia Bai
Chenjia Bai
Home
Book
Publications
Team
Join us
Light
Dark
Automatic
Under-Review
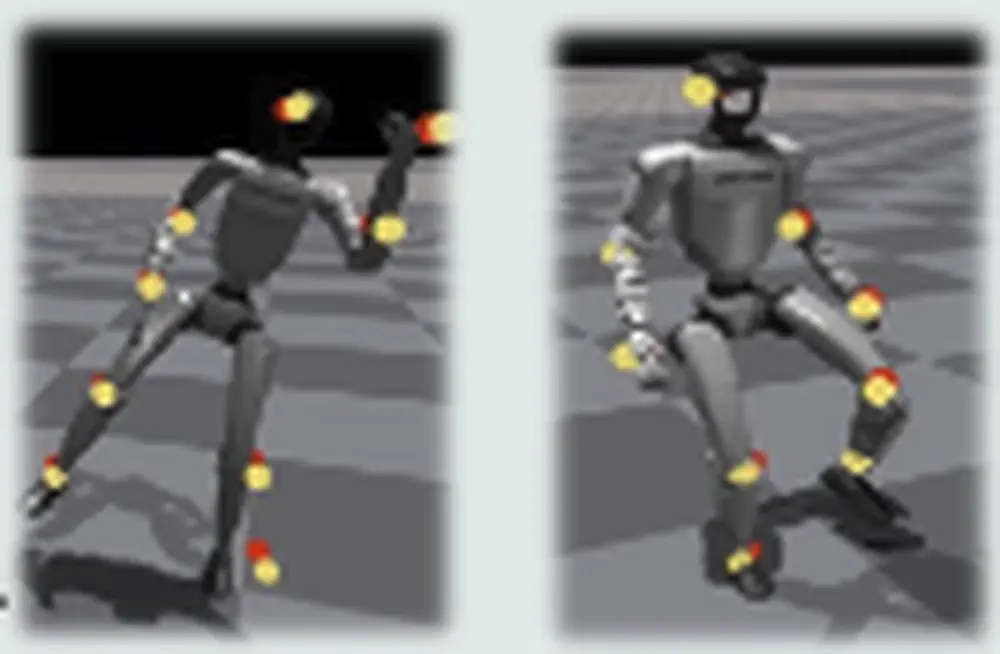
KungfuBot2: Learning Versatile Motion Skills for Humanoid Whole-Body Control
under review
We present VMS, a unified whole-body controller that enables humanoid robots to learn diverse and dynamic behaviors within a single policy through hybrid tracking and orthogonal mixture of experts.
Jinrui Han
,
Weiji Xie
,
Jiakun Zheng
,
Jiyuan Shi
,
Weinan Zhang
,
Ting Xiao
,
Chenjia Bai
✉
PDF
Cite
Project
MoRE: Mixture of Residual Experts for Humanoid Lifelike Gaits Learning on Complex Terrains
under review
We propose a novel framework that enables humanoid robots to traverse complex terrains with controllable human-like gaits using a mixture of latent residual experts and multi-discriminators.
Dewei Wang
,
Xinmiao Wang
,
Xinzhe Liu
,
Jiyuan Shi
,
Yingnan Zhao
,
Chenjia Bai
✉
,
Xuelong Li
✉
PDF
Cite
Project
Learn as Individuals, Evolve as a Team: Multi-agent LLMs Adaptation in Embodied Environments
under review
We propose the Learn as Individuals, Evolve as a Team (LIET) framework to enable multi-agent LLMs to adapt to embodied environments through individual learning and team evolution
Xinran Li
,
Chenjia Bai
✉
,
Zijian Li
,
Jiakun Zheng
,
Ting Xiao
,
Jun Zhang
✉
PDF
Cite
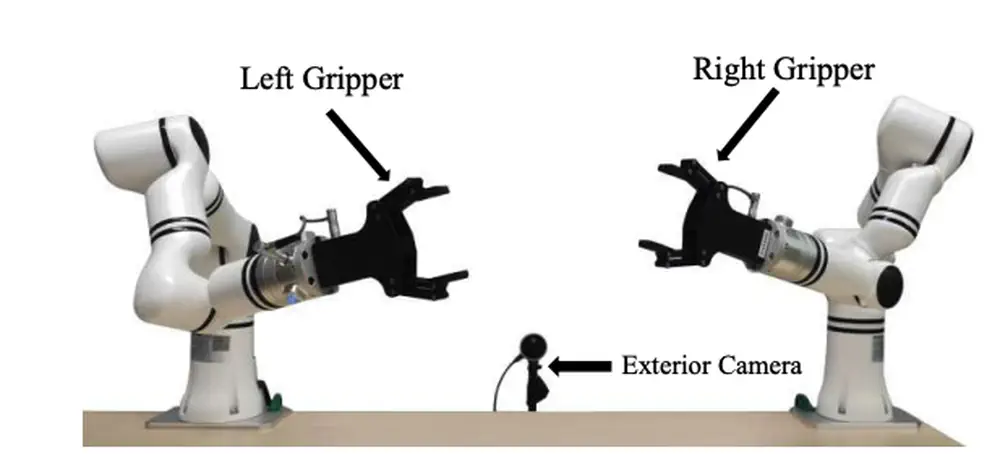
Towards a Generalizable Bimanual Foundation Policy via Flow-based Video Prediction
under review
We propose a novel bimanual foundation policy that leverages text-to-video models to predict robot trajectories and uses optical flow as an intermediate variable to improve generalization.
Chenyou Fan
,
Fangzheng Yan
,
Chenjia Bai
✉
,
Jiepeng Wang
,
Chi Zhang
,
Zhen Wang
,
Xuelong Li
✉
PDF
Cite
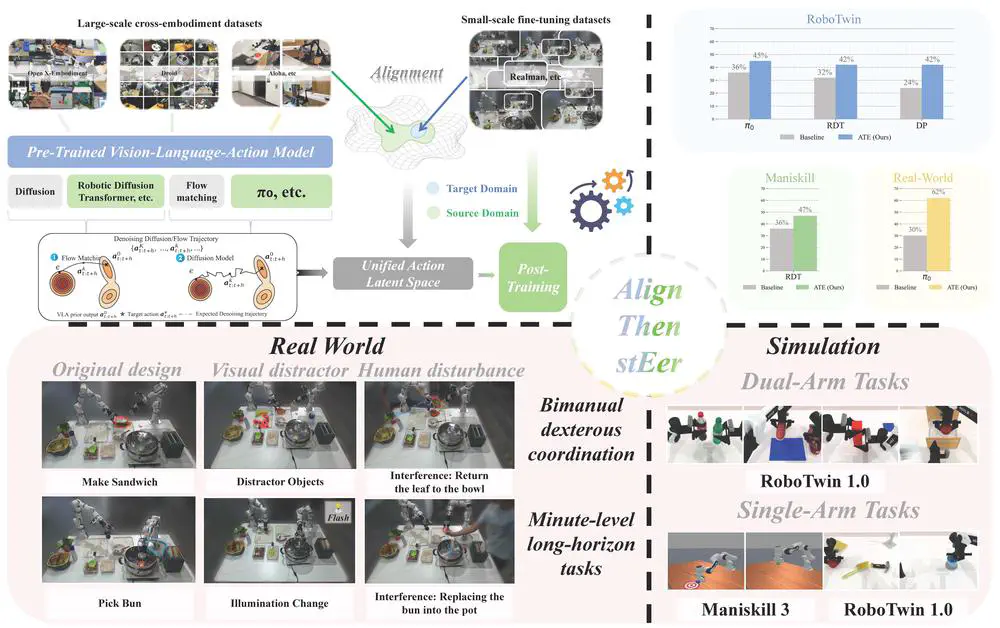
Align-Then-stEer: Adapting the Vision-Language Action Models through Unified Latent Guidance
under review
We propose Align-Then-stEer (ATE), a framework that adapts VLAs to novel robots and tasks through unified latent guidance. ATE can handle significant domain shifts without compromising performance and compatible to Pi0, RDT, and etc.
Yang Zhang
,
Chenwei Wang
,
Ouyang Lu
,
Yuan Zhao
,
Yunfei Ge
,
Zhenglong Sun
,
Xiu Li
,
Chi Zhang
,
Chenjia Bai
✉
,
Xuelong Li
✉
PDF
Cite
Code
Project
公众号
Cite
×