 Image credit: Chenjia Bai
Image credit: Chenjia BaiAbstract
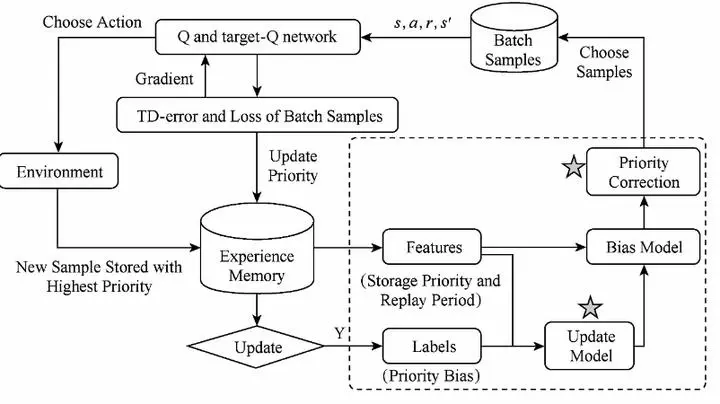
Deep reinforcement learning (DRL) is one of research hotspots in artificial intelligence. Deep Q-learning is one of the representative achievements of DRL. In some fields, its performance has met or exceeded the level of human expert. It is necessary for training deep Q-learning to acquire lots of samples. These samples are obtained by the interaction between agent and environment. However, it is usually computationally intensive and sometimes impossible to keep away from interaction risk. We propose an active sampling method based on TD-error adaptive correction in order to solve sample efficiency problem in deep Q-learning. In various deep Q-learning methods, the updating of storage priority in experience memory lags behind the updating of Q-network parameters. It causes that a lot of samples are not selected to apply in Q-network training because the storage priority cannot reflect the true distribution of TD-error in experience memory. The TD-error adaptive correction active sampling method proposed in this paper uses the replay periods of samples and Q-network state to establish a priority bias model to estimate the real priority of each sample in experience memory during the Q-network iteration. The samples are selected from experience memory according to the corrected priority and the bias model parameters are adaptively updated by a segmented form. We analyze the complexity of the algorithm and the relationship between learning performance and the order of polynomial feature and updating period of model parameters. Our method is verified on the platform of Atari 2600. The experimental results show that proposed method improves the learning speed and reduces the number of interaction between agent and environment. Meanwhile, it ameliorates the quality of optimal policy.