Align-Then-stEer: Adapting the Vision-Language Action Models through Unified Latent Guidance
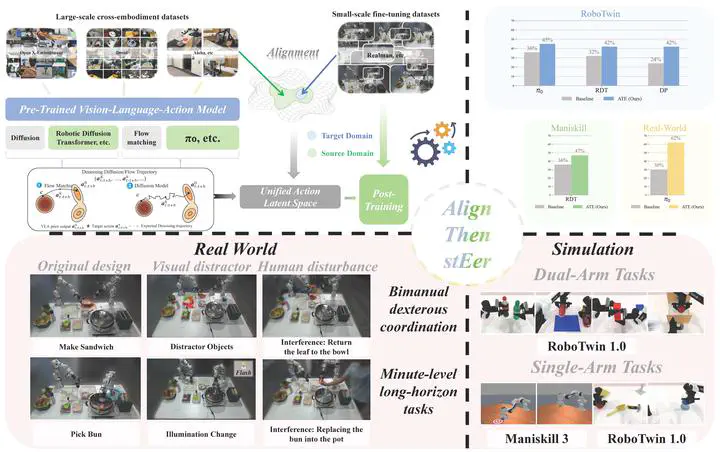 Image credit: Chenjia Bai
Image credit: Chenjia BaiAbstract
Vision-Language Action Models (VLAs) demonstrate remarkable capabilities in mapping language instructions to robot actions through vision perception. However, their limited ability to adapt to novel environments poses a significant challenge to real-world deployment. Existing methods tackle this by either fine-tuning the entire model or pre-training on large-scale embodied datasets, which can be computationally intensive or prone to catastrophic forgetting. To address this, we propose Align-Then-stEer (ATE), a framework that adapts VLAs to novel environments through unified latent guidance. Specifically, ATE incorporates an environment-specific adapter to guide the latent representation of the original model. This adapter is trained via contrastive learning on a small amount of domain data, enabling efficient adaptation while preserving the model’s original capabilities. We validate ATE on both simulation and real-world benchmarks, demonstrating its effectiveness in adapting VLAs to novel environments with limited data and computational resources. Moreover, we show that ATE can handle significant domain shifts without compromising performance on the original domain.