 Image credit: Chenjia Bai
Image credit: Chenjia BaiAbstract
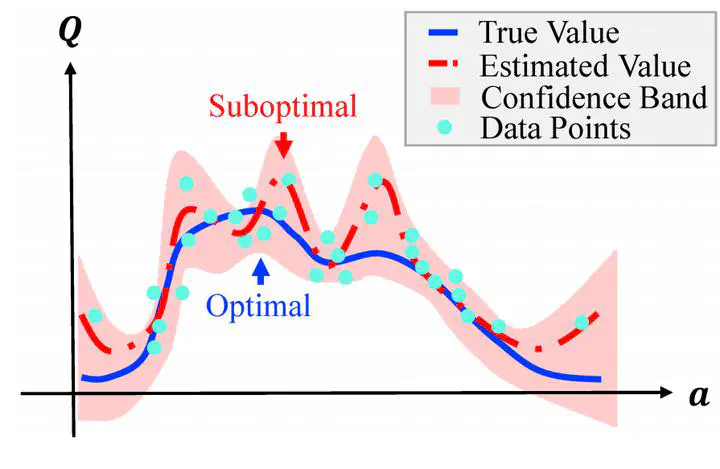
Offline reinforcement learning (RL) harnesses the power of massive datasets for resolving sequential decision problems. Most existing papers only discuss defending against out-of-distribution (OOD) actions while we investigate a broader issue, the false correlations between epistemic uncertainty and decision-making, an essential factor that causes suboptimality. In this paper, we propose falSe COrrelation REduction (SCORE) for offline RL, a practically effective and theoretically provable algorithm. We empirically show that SCORE achieves the SoTA performance with 3.1x acceleration on various tasks in a standard benchmark (D4RL). The proposed algorithm introduces an annealing behavior cloning regularizer to help produce a high-quality estimation of uncertainty which is critical for eliminating false correlations from suboptimality. Theoretically, we justify the rationality of the proposed method and prove its convergence to the optimal policy with a sublinear rate under mild assumptions.