 Image credit: Chenjia Bai
Image credit: Chenjia BaiAbstract
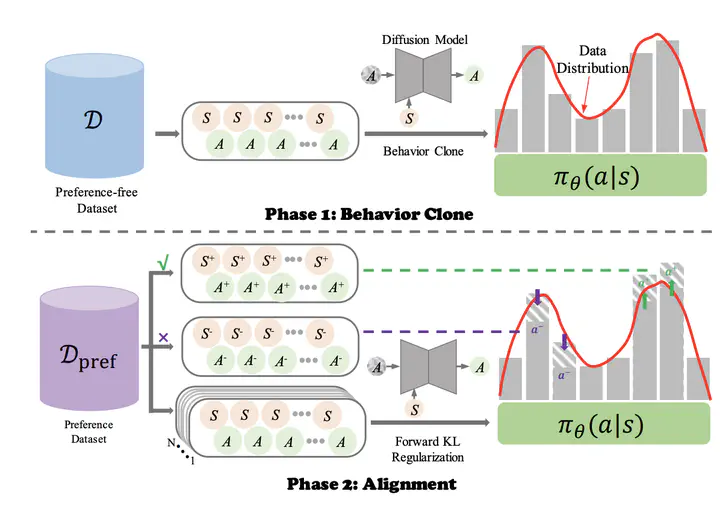
Diffusion models have achieved remarkable success in sequential decision-making by leveraging the highly expressive model capabilities in policy learning. A central problem for learning diffusion policies is to align the policy output with human intents in various tasks. To achieve this, previous methods conduct return-conditioned policy generation or Reinforcement Learning (RL)-based policy optimization, while they both rely on pre-defined reward functions. In this work, we propose a novel framework, Forward KL regularized Preference optimization for aligning Diffusion policies, to align the diffusion policy with preferences directly. We first train a diffusion policy from the offline dataset without considering the preference, and then align the policy to the preference data via direct preference optimization. During the alignment phase, we formulate direct preference learning in a diffusion policy, where the forward KL regularization is employed in preference optimization to avoid generating out-of-distribution actions. We conduct extensive experiments for MetaWorld manipulation and D4RL tasks. The results show our method exhibits superior alignment with preferences and outperforms previous state-of-the-art algorithms.