 Image credit: Chenjia Bai
Image credit: Chenjia BaiAbstract
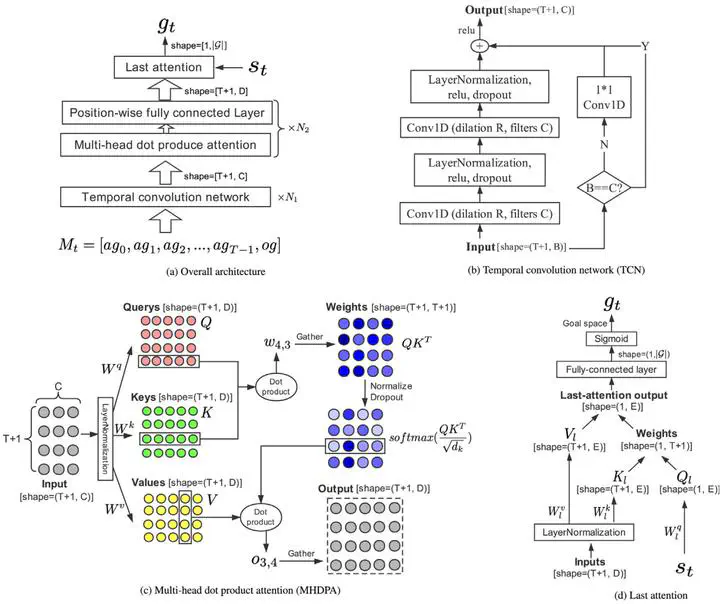
Typical reinforcement learning (RL) performs a single task and does not scale to problems in which an agent must perform multiple tasks, such as moving a robot arm to different locations. The multi-goal framework extends typical RL using a goal-conditional value function and policy, whereby the agent pursues different goals in different episodes. By treating a virtual goal as the desired one, and frequently giving the agent rewards, hindsight experience replay has achieved promising results in the sparse-reward setting of multi-goal RL. However, these virtual goals are uniformly sampled after the replay state from experiences, regardless of their significance. We propose a novel prioritized hindsight model for multi-goal RL in which the agent is provided with more valuable goals, as measured by the expected temporal-difference (TD) error. An attentive goals generation (AGG) network, which consists of temporal convolutions, multi-head dot product attentions, and a last-attention network, is structured to generate the virtual goals to replay. The AGG network is trained by following the gradient of TD-error calculated by an actor–critic model, and generates goals to maximize the expected TD-error with replay transitions. The whole network is fully differentiable and can be learned in an end-to-end manner. The proposed method is evaluated on several robotic manipulating tasks and demonstrates improved sample efficiency and performance.