Learning an Actionable Discrete Diffusion Policy via Large-Scale Actionless Video Pre-Training.
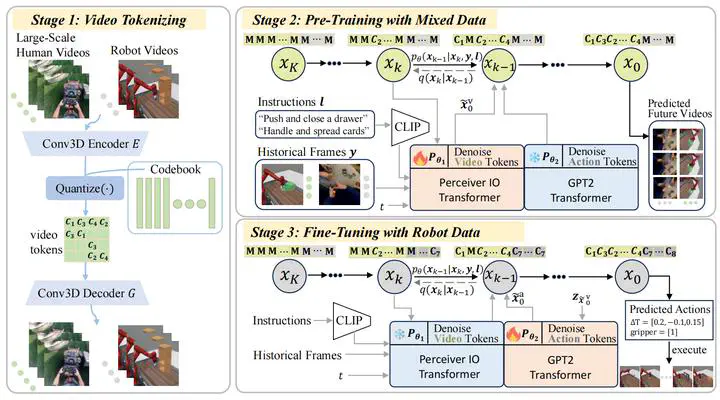 Image credit: Chenjia Bai
Image credit: Chenjia BaiAbstract
Learning a generalist embodied agent capable of completing multiple tasks poses challenges, primarily stemming from the scarcity of action-labeled robotic datasets. In contrast, a vast amount of human videos exist, capturing intricate tasks and interactions with the physical world. Promising prospects arise for utilizing actionless human videos for pre-training and transferring the knowledge to facilitate robot policy learning through limited robot demonstrations. However, it remains a challenge due to the domain gap between humans and robots. Moreover, it is difficult to extract useful information representing the dynamic world from human videos, because of its noisy and multimodal data structure. In this paper, we introduce a novel framework to tackle these challenges, which leverages a unified discrete diffusion to combine generative pre-training on human videos and policy fine-tuning on a small number of action-labeled robot videos. We start by compressing both human and robot videos into unified video tokens. In the pre-training stage, we employ a discrete diffusion model with a mask-and-replace diffusion strategy to predict future video tokens in the latent space. In the fine-tuning stage, we harness the imagined future videos to guide low-level action learning with a limited set of robot data. Experiments demonstrate that our method generates high-fidelity future videos for planning and enhances the fine-tuned policies compared to previous state-of-the-art approaches with superior performance.