 Image credit: Chenjia Bai
Image credit: Chenjia BaiAbstract
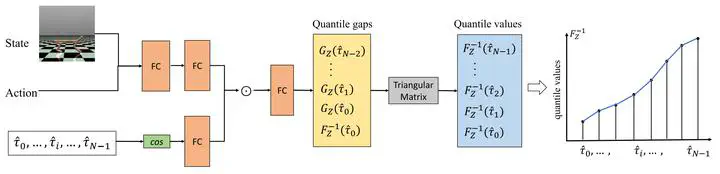
A key challenge in offline reinforcement learning (RL) is how to ensure the learned offline policy is safe, especially in safety-critical domains. In this article, we focus on learning a distributional value function in offline RL and optimizing a worst-case criterion of returns. However, optimizing a distributional value function in offline RL can be hard, since the crossing quantile issue is serious, and the distribution shift problem needs to be addressed. To this end, we propose monotonic quantile network (MQN) with conservative quantile regression (CQR) for risk-averse policy learning. First, we propose an MQN to learn the distribution over returns with non-crossing guarantees of the quantiles. Then, we perform CQR by penalizing the quantile estimation for out-of-distribution (OOD) actions to address the distribution shift in offline RL. Finally, we learn a worst-case policy by optimizing the conditional value-at-risk (CVaR) of the distributional value function. Furthermore, we provide theoretical analysis of the fixed-point convergence in our method. We conduct experiments in both risk-neutral and risk-sensitive offline settings, and the results show that our method obtains safe and conservative behaviors in robotic locomotion tasks.