Pessimistic Value Iteration for Multi-Task Data Sharing in Offline Reinforcement Learning.
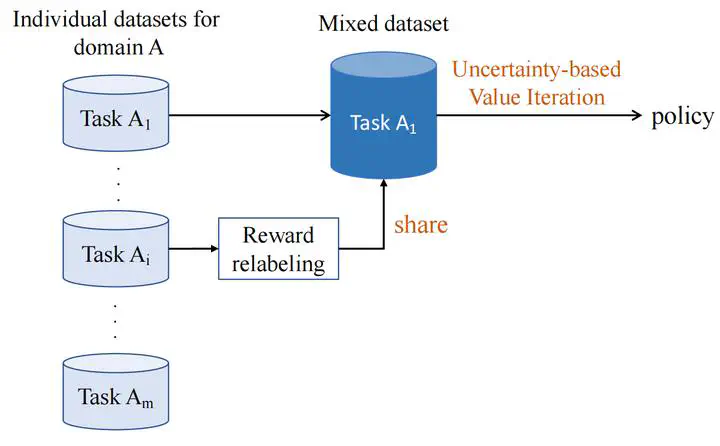 Image credit: Chenjia Bai
Image credit: Chenjia BaiAbstract
Offline Reinforcement Learning (RL) has shown promising results in learning a task-specific policy from a fixed dataset. However, successful offline RL often relies heavily on the coverage and quality of the given dataset. In scenarios where the dataset for a specific task is limited, a natural approach is to improve offline RL with datasets from other tasks, namely, to conduct Multi-Task Data Sharing (MTDS). Nevertheless, directly sharing datasets from other tasks exacerbates the distribution shift in offline RL. In this paper, we propose an uncertainty-based MTDS approach that shares the entire dataset without data selection. Given ensemble-based uncertainty quantification, we perform pessimistic value iteration on the shared offline dataset, which provides a unified framework for single- and multi-task offline RL. We further provide theoretical analysis, which shows that the optimality gap of our method is only related to the expected data coverage of the shared dataset, thus resolving the distribution shift issue in data sharing. Empirically, we release an MTDS benchmark and collect datasets from three challenging domains. The experimental results show our algorithm outperforms the previous state-of-the-art methods in challenging MTDS problems.