 Image credit: Chenjia Bai
Image credit: Chenjia BaiAbstract
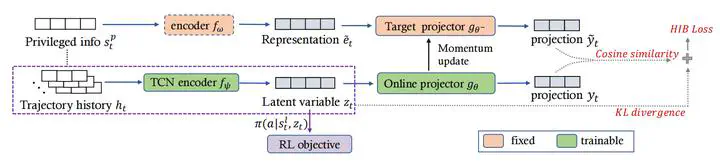
Reinforcement Learning (RL) has recently achieved remarkable success in robotic control. However, most works in RL operate in simulated environments where privileged knowledge (e.g., dynamics, surroundings, terrains) is readily available. Conversely, in real-world scenarios, robot agents usually rely solely on local states (e.g., proprioceptive feedback of robot joints) to select actions, leading to a significant sim-to-real gap. Existing methods address this gap by either gradually reducing the reliance on privileged knowledge or performing a two-stage policy imitation. However, we argue that these methods are limited in their ability to fully leverage the available privileged knowledge, resulting in suboptimal performance. In this paper, we formulate the sim-to-real gap as an information bottleneck problem and therefore propose a novel privileged knowledge distillation method called the Historical Information Bottleneck (HIB). In particular, HIB learns a privileged knowledge representation from historical trajectories by capturing the underlying changeable dynamic information. Theoretical analysis shows that the learned privileged knowledge representation helps reduce the value discrepancy between the oracle and learned policies. Empirical experiments on both simulated and real-world tasks demonstrate that HIB yields improved generalizability compared to previous methods.