 Image credit: Chenjia Bai
Image credit: Chenjia BaiAbstract
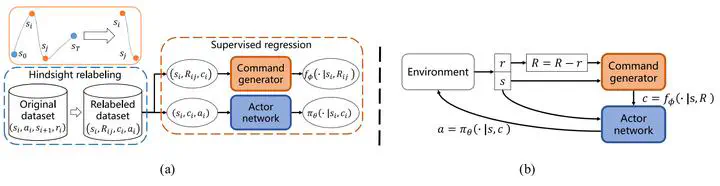
Reinforcement learning (RL) requires a lot of interactions with the environment, which is usually expensive or dangerous in real-world tasks. To address this problem, offline RL considers learning policies from fixed datasets, which is promising in utilizing large-scale datasets, but still suffers from the unstable estimation for out-of-distribution data. Recent developments in RL via supervised learning methods offer an alternative to learning effective policies from suboptimal datasets while relying on oracle information from the environment. In this article, we present an offline RL algorithm that combines hindsight relabeling and supervised regression to predict actions without oracle information. We use hindsight relabeling on the original dataset and learn a command generator and command-conditional policies in a supervised manner, where the command represents the desired return or goal location according to the corresponding task. Theoretically, we illustrate that our method optimizes the lower bound of the goal-conditional RL objective. Empirically, our method achieves competitive performance in comparison with existing approaches in the sparse reward setting and favorable performance in continuous control tasks.