 Image credit: Chenjia Bai
Image credit: Chenjia BaiAbstract
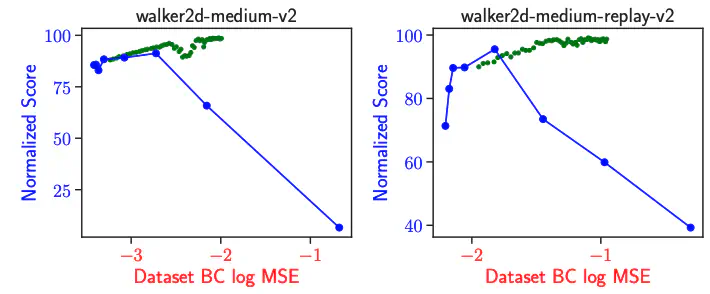
Policy constraint methods in offline reinforcement learning employ additional regularization techniques to constrain the discrepancy between the learned policy and the offline dataset. However, these methods tend to result in overly conservative policies that resemble the behavior policy, thus limiting their performance. We investigate this limitation and attribute it to the static nature of traditional constraints. In this paper, we propose a novel dynamic policy constraint that restricts the learned policy on the samples generated by the exponentional moving average of previously learned policies. By integrating this self-constraint mechanism into off-policy methods, our method facilitates the learning of unconservative policies while avoiding policy collapse in the offline setting. Theoretical results show that our approach results in a nearly monotonically improved reference policy. Extensive experiments on the D4RL MuJoCo domain demonstrate that our proposed method achieves state-of-the-art performance among the policy constraint methods.