 Image credit: Chenjia Bai
Image credit: Chenjia BaiAbstract
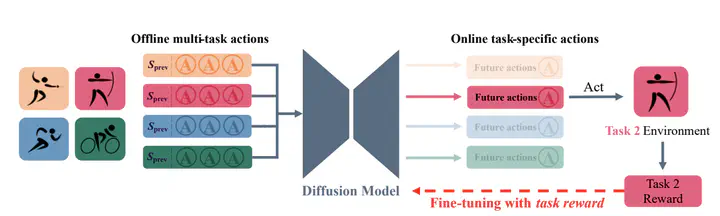
Diffusion models have demonstrated their capabilities in modeling trajectories of multi-tasks. However, existing multi-task planners or policies typically rely on task-specific demonstrations via multi-task imitation, or require task-specific reward labels to facilitate policy optimization via Reinforcement Learning (RL). To address these challenges, we aim to develop a versatile diffusion planner that can leverage large-scale inferior data that contains task-agnostic sub-optimal trajectories, with the ability to fast adapt to specific tasks. In this paper, we propose extbf{SODP}, a two-stage framework that leverages extbf{S}ub- extbf{O}ptimal data to learn a extbf{D}iffusion extbf{P}lanner, which is generalizable for various downstream tasks. Specifically, in the pre-training stage, we train a foundation diffusion planner that extracts general planning capabilities by modeling the versatile distribution of multi-task trajectories, which can be sub-optimal and has wide data coverage. Then for downstream tasks, we adopt RL-based fine-tuning with task-specific rewards to fast refine the diffusion planner, which aims to generate action sequences with higher task-specific returns. Experimental results from multi-task domains including Meta-World and Adroit demonstrate that SODP outperforms state-of-the-art methods with only a small amount of data for reward-guided fine-tuning.