 Image credit: Chenjia Bai
Image credit: Chenjia BaiAbstract
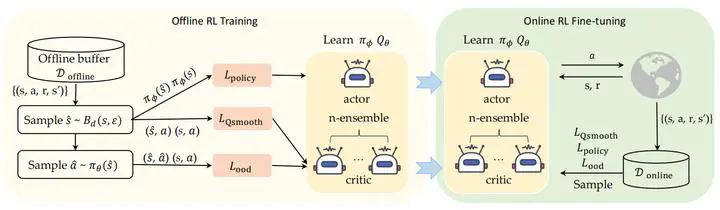
To obtain a near-optimal policy with fewer interactions in Reinforcement Learning (RL), a promising approach involves the combination of offline RL, which enhances sample efficiency by leveraging offline datasets, and online RL, which explores informative transitions by interacting with the environment. Offline-to-Online RL provides a paradigm for improving an offline-trained agent within limited online interactions. However, due to the significant distribution shift between online experiences and offline data, most offline RL algorithms suffer from performance drops and fail to achieve stable policy improvement in offline-to-online adaptation. To address this problem, we propose the Robust Offlineto-Online (RO2O) algorithm, designed to enhance offline policies through uncertainty and smoothness, and to mitigate the performance drop in online adaptation. Specifically, RO2O incorporates Q-ensemble for uncertainty penalty and adversarial samples for policy and value smoothness, which enable RO2O to maintain a consistent learning procedure in online adaptation without requiring special changes to the learning objective. Theoretical analyses in linear MDPs demonstrate that the uncertainty and smoothness lead to tighter optimality bound in offline-to-online against distribution shift. Experimental results illustrate the superiority of RO2O in facilitating stable offline-to-online learning and achieving significant improvement with limited online interactions.